前回のおさらい
前回の記事では、React CompilerがASTをHIRに変換するプロセスを見てきました。
HIR(High-level Intermediate Representation)は、CFG(Control Flow Graph)を使用してASTを変換した中間表現でした。
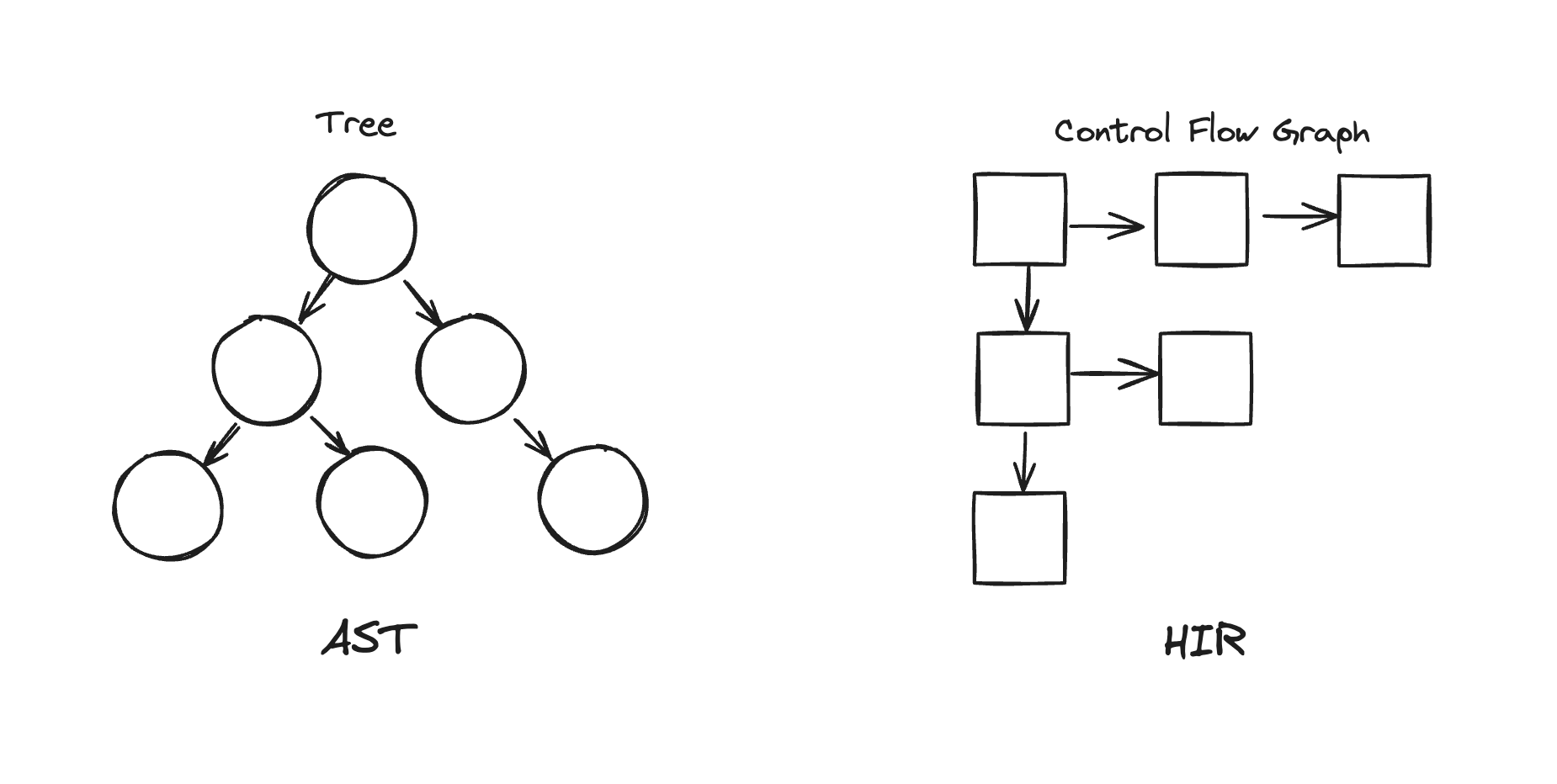
そのためHIRはブロックと制御フローを通じてコード全体の流れを示すことができます。
その次は?
しかし、より詳細な最適化を行うには、基本的なHIRの形だけでは不十分です。
何がさらに必要なのでしょうか?
最適化プロセスの一つである、定数伝播(constant propagation)を例に見ていきましょう。
定数伝播とは、変数に定数が代入されている場合、その変数を定数に置き換える最適化手法です。
簡単に説明すると、事前に代入できるものを代入しておくということです。
例を挙げてみましょう。
x = 5
y = x + 2
x = 10
z = x + yこのようなコードがあると仮定しましょう。(実際にはHIR形式に変換されたコードでしょう?)
ここでdef-useチェーンという概念を使います。
def-useチェーンは変数の代入(def)と使用(use)の関係を意味します。
xの最初の代入(def)x = 5はy = x + 2で使用(use)されますが、z = x + yには影響しません。
そしてxの2番目の代入x = 10はz = x + yで使用されます。
y = x + 2で使用されたxの値とz = x + yで使用されたxの値は異なることがわかります。
このような複雑な関係を追跡するには、より詳細なデータフロー分析が必要です。
そのためHIRをSSAに変換するプロセスが必要なのです。
変換すると以下のようになります。
x1 = 5
y1 = x1 + 2
x2 = 10
z1 = x2 + y1おお!変数にインデックスが付きました。xがx1、x2に分かれています。
このように変換すると、def-useチェーンを追跡するのがはるかに簡単になります。自分が使っているxがどのxなのかわかるようになります。
これで、もっと自信を持ってyは7で、zは17だと言えますよね?
このように置き換え可能な変数を置き換えておくのが定数伝播最適化です。
そしてSSA形式を通じてこのような作業が簡単にできることも素早く確認できました。
今回の記事ではHIRをSSAに変換するプロセスを見ていきます。
まずSSAが何かを知っておく必要がありますよね?
ちょっと待って!定数伝播はSSA変換をしなくても求めることができます。この場合到達定義分析という方法を使うことができます。
興味のある方だけ読んでいただき、すぐ下に進んでいただいても構いません。
SSA(静的単一代入、Static Single Assignment)
SSAは静的単一代入という意味で、最適化のために使用される中間表現の一つです。
SSAは変数が一度だけ代入されるように制限する特徴があります。
これは上で簡単な例を示したようにdef-useチェーンを追跡しやすくする助けとなります。
先ほどの例をもう一度見てみましょう。
x = 5
y = x + 2
x = 10
z = x + y何度も定義され代入されるこのx、y、z変数を以下のように変換しました。
x1 = 5
y1 = x1 + 2
x2 = 10
z1 = x2 + y1各変数に一つの定義のみを与えるように変換してdef-useチェーンをシンプルにしたわけです。 これにより各変数の負担を軽減し、データの流れの把握がより容易になります。
思ったより簡単ですよね?
それでは、こういうケースはどのように変換できるでしょうか?
if(condition){
x = 5
} else {
x = 10
}
y = x + 2数行しかないコードですが、すぐに変換してみましょう。
if(condition){
x1 = 5
} else {
x2 = 10
}
// ...新しいxに出会うたびに新しい変数にうまく置き換えました。
ここまではスムーズに変換できましたが、次の行で壁にぶつかります。
y1 = x + 2 // yはy1に変えればいいけど... xは何に変えればいい?conditionによってxが決まるはずなのに、どのxが入るのか表す方法がまだわかりません。
上のケースはxがif-else文の条件によって異なる値を持つ可能性がある場合です。
y = x + 2で使用されたxがどのxなのかわかりません。条件文に出会うと以前の例のように簡単にxを入れることができません。
我慢できず先に答えを見てみましょう。
SSAに変換すると以下のようになります。
if(condition){
x1 = 5
} else {
x2 = 10
}
x3 = φ(x1, x2)
y1 = x3 + 2φ(以下「phi」)という関数が登場しました。
phiはif-else文のような分岐によって異なる値を持つ可能性のある変数を結合する関数です。
これによりx3を新しい変数として作り、φ関数を通じてif-else文の条件に応じてx1とx2のどちらかを選択することになります。
φ関数の役割を別の言い方で表現すると、分岐を合流させる関数とも言えるでしょう。
タイムトラベル映画のように、選択によって分岐した二つのパラレルワールドのxを再び一つに合わせるように見えます。

SSAの主要な概念をまとめると以下のようになります。
- 各変数の単一定義:
- SSA形式では各変数はプログラム内で一度だけ定義されます。つまり、同じ変数名が複数回定義されることはありません。そのため、変数を定義するたびに新しい名前(例:x1、x2、x3)を付与します。
- φ(phi)関数:
- 制御フローが合流するポイントでは複数の定義を一つにまとめるφ(phi)関数を使用します。φ関数は制御フローのどの経路を通って到達したかに応じて異なる値を選択します。
これで意味的にはphi関数をどこに置くべきかは簡単に理解できます。
「適切な分岐の合流地点に置く。」 このようにまとめることができるでしょう。
しかしこれを論理的に表現するには、どうすればよいでしょうか?
SSA変換アルゴリズム
SSA変換アルゴリズムの核心はphi関数をどこに置くかを決定することです。
React Compilerの場合、コミットを見ると以下の論文(Simple and Efficient Construction of Static Single Assignment Form)のアルゴリズムを使用しています。
Add SSA-ify pass · facebook/react@379251c
The algorithm is described in detail here: https://pp.info.uni-karlsruhe.de/uploads/publikationen/braun13cc.pdf Note that the SSA form generated is not minimal. A follow on RedundantPhiElimina...
https://github.com/facebook/react/commit/379251c65f39039ace1d2e5a80bdb5938cf3427c// commit message
The algorithm is described in detail here:
https://pp.info.uni-karlsruhe.de/uploads/publikationen/braun13cc.pdf
// リンクが間違っていたため差し替えました。
Note that the SSA form generated is not minimal. A follow on
RedundantPhiElimination pass
is required to prune the graph.Simple and Efficient Construction of Static Single Assignment Form
Matthias Braun1, Sebastian Buchwald1, Sebastian Hack2, Roland Leißa2, Christoph Mallon2, and Andreas Zwinkau
https://pp.ipd.kit.edu/uploads/publikationen/braun13cc.pdfこの論文ではCytron et al.のアルゴリズムに対する改良版を提案しています。
既存のアルゴリズムと比べてよりシンプルで効率的だとされています。
それではこの利点を実感するために、Cytronのアルゴリズムをまず見てみるのがよいでしょう。(次のチャプターにそのまま進んでいただいても構いません。)
Cytronのアルゴリズム
Efficiently Computing Static Single Assignment form and the Control Dependence Graph for ACM TOPLAS
Efficiently Computing Static Single Assignment form and the Control Dependence Graph for ACM TOPLAS by Ron Cytron et al.
https://research.ibm.com/publications/efficiently-computing-static-single-assignment-form-and-the-control-dependence-graphこの論文は1991年にIBM Researchで発表されたもので、SSAを生成するアルゴリズムの一つです。
主要な概念はドミネーターツリーとドミナンスフロンティアです。
- ドミネーターツリー(Dominator Tree)の構築: プログラムの制御フローグラフ(CFG)における各ノード間の支配関係を表すツリーを構築します。
- ドミナンスフロンティア(Dominance Frontier)の計算: 各ノードに対してドミナンスフロンティアを計算します。ドミナンスフロンティアはノードが直接支配しない最も近い子孫ノードの集合です。
私たちが知りたかったのはphi関数をどこに置くべきかということなので、それを目的に論文を探っていきましょう。
このアルゴリズムではまずツリー全体に対する分析が行われます。これによりドミネーターツリーを構築しドミナンスフロンティアを計算します。
そしてこれを通じてphi関数をどこに置くべきかを決定します。
ドミネーターツリー(Dominator Tree)
まずドミネーターツリー(Dominator Tree)とは何でしょうか?
ここで支配(Dominance)、ノードAがノードBを支配するとは、Bへのすべての経路がAを通過しなければならないことを意味します。
またすべてのノードは自分自身を支配すると仮定します。
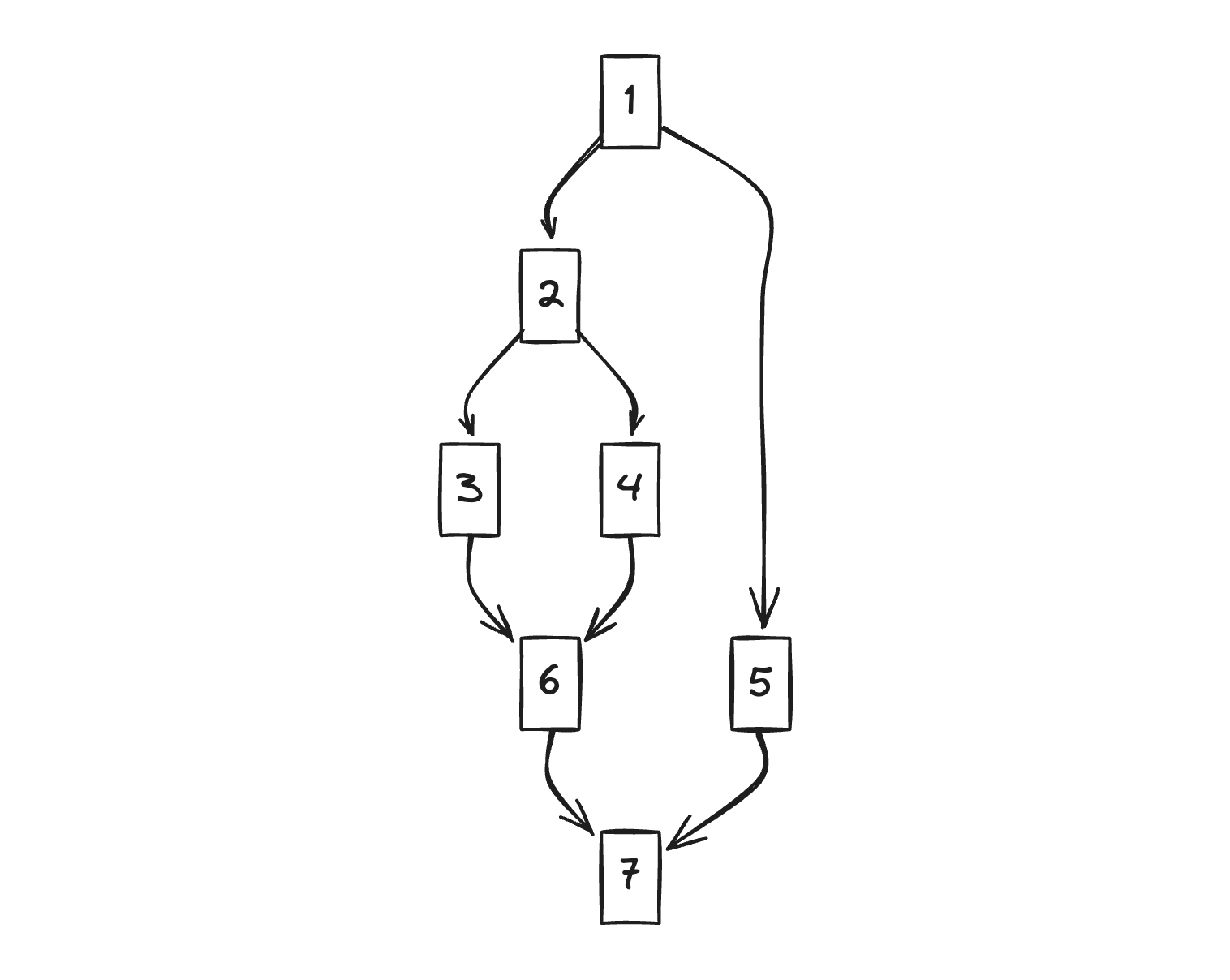
このCFG(私たちの場合はHIRになりますね?)があると仮定して支配関係を見てみましょう。
- 2番と5番は必ず1番を通らなければなりません。したがって1番が2番と5番を支配します。
- 3番と4番は必ず1番、2番を通らなければなりません。しかし支配関係では最も近い支配者のみを考慮します。したがって2番が3番を支配します。
- 6番の場合は3番、4番が親ですが、必ず通過しなければならないわけではありません。そこで一段上に上がってみると2番は必ず通らなければなりません。したがって2番が6番を支配します。
- 7番の場合も同様に6番と5番を通って来ることができます。したがって各ルートをたどっていくと1番を必ず通らなければならないことがわかります。したがって1番が7番を支配します。
この関係を再びツリー(ドミネーターツリー)で表現すると以下のようになります。
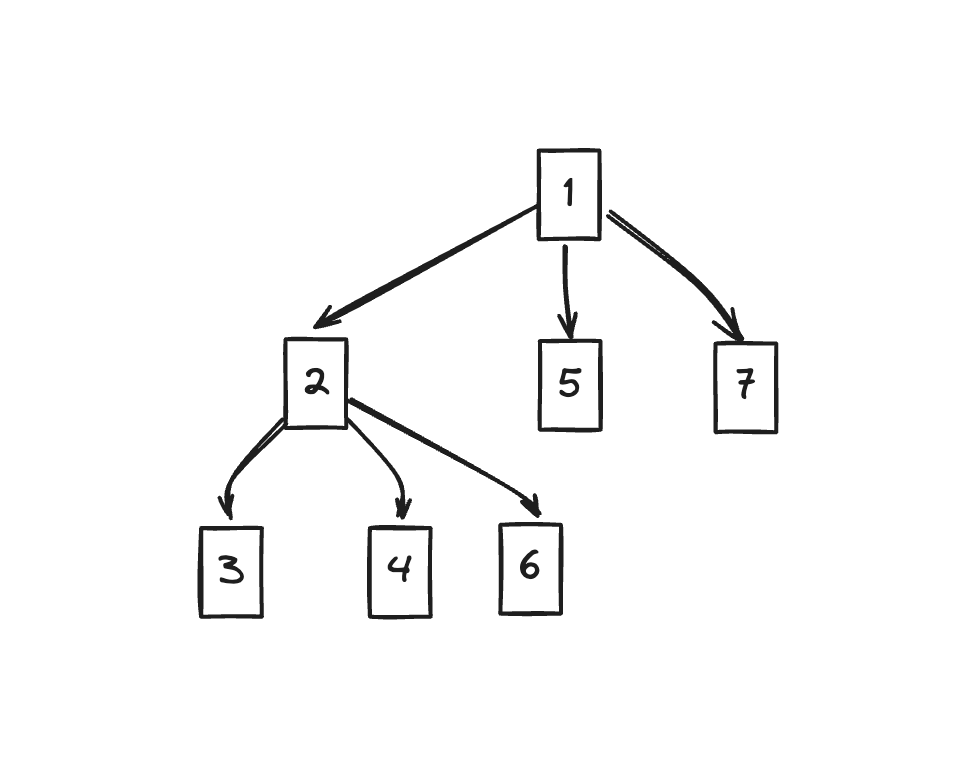
上で見てきた支配関係どおりに表現されていますよね?
元のCFGと一見似て見えますが、少し違う姿を見せています。
必ず通らなければならないため、大きな分岐を持つものは分岐前のノードが支配していることが見て取れます。(7が代表的ですね)
ドミナンスフロンティア(Dominance Frontier)
次にドミナンスフロンティア(Dominance Frontier)を計算します。
ノードNのドミナンスフロンティア(DF)は次のように定義されます:
- Nが直接支配しないが、Nが直接支配するノードが支配するCFGのノードの集合
直感的には、DF(N)はNの支配力が終わるポイントと考えることができます。
これはどういう意味でしょうか? 一度ではなかなか理解しづらいですね。
図を使って2と5のドミナンスフロンティアDFを求めるプロセスを一緒に見ていきましょう。
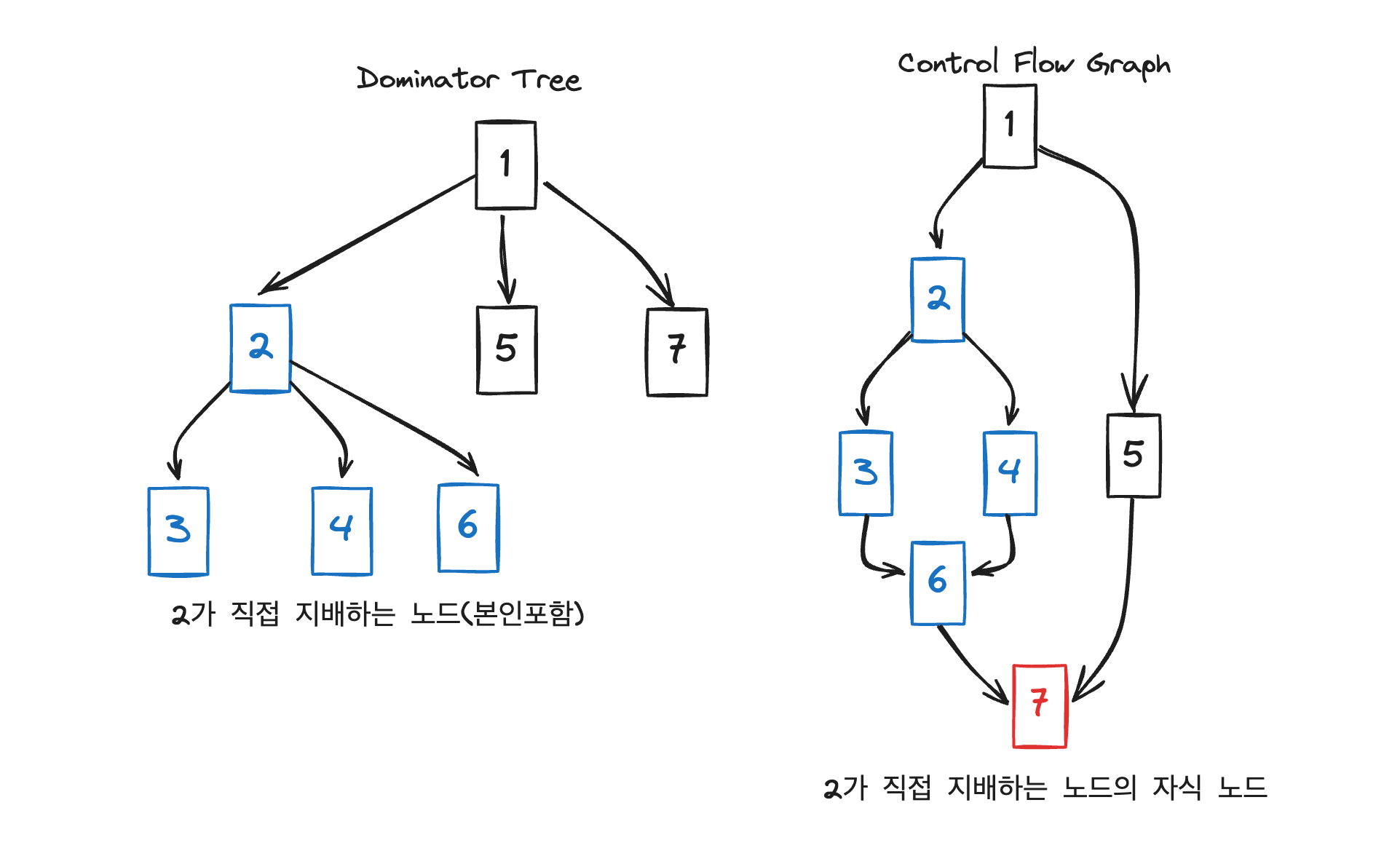
2の場合、3、4、6そして2(自分自身)を支配します。
それでは支配している2、3、4、6の子の中で2が支配しないノードを探すと、6の子である7を見つけることができます。
したがってDF(2)は7になります。
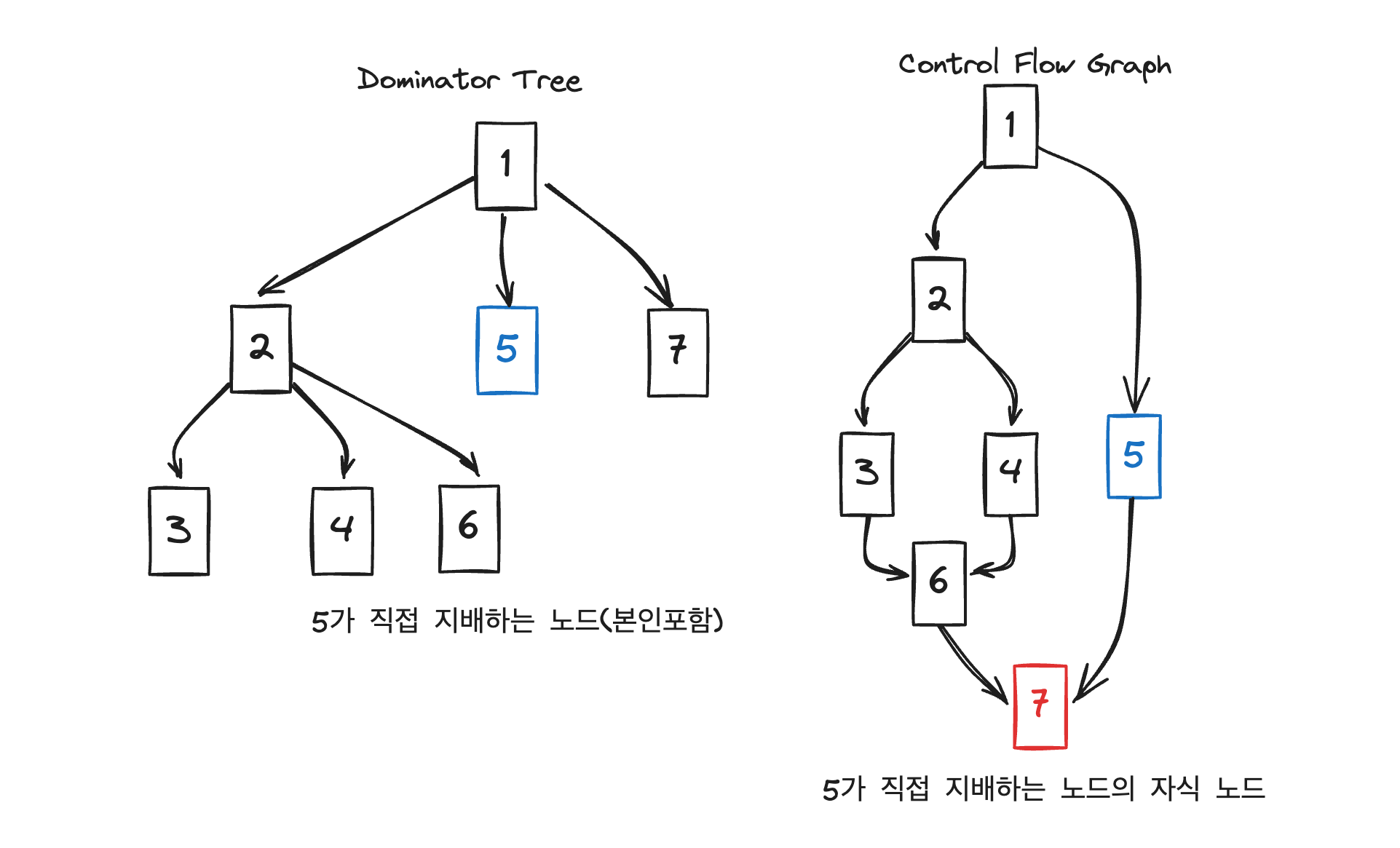
5の場合、ドミネーターツリーを見ると自分自身しかいません。
CFGで5が支配しないノードは子の7になります。
したがってDF(5)は7になります。
このようにしてドミナンスフロンティアを計算します。各場合をすべて見てみると以下のようになります。
DF(1) = {} // 1はすべてのノードを支配するのでDFがない
DF(2) = {7}
DF(3) = {6}
DF(4) = {6}
DF(5) = {7}
DF(6) = {7}
DF(7) = {}完全に理解できなくても、大体どのようにDFを見つけることができるかわかるようになりました。
DFにあるノードにphi関数を置きます。
まだすっきりしない部分があるかもしれません。グラフで遊んでいるように見えますよね。
それではドミナンスフロンティアの定義から意味を分析してみましょう。
DF(X) = Y、XのドミナンスフロンティアはYという意味を見てみましょう。YはXの支配力が終わるポイントと見ることができます。
- DFの定義によりYはXが支配するノードの子ノードです。
つまりXを通ってYへ行く経路があることを意味します。 - DFの定義によりYはXの直接支配関係ではない。
つまりYへ行く経路が必ずしもXを通るわけではないことを意味します。
総合するとYはXを通っても行けるし、別の経路でも行けるノードです。
つまり少なくとも二つの経路でYに向かうことができるということになりますね。
それはつまり分岐が合流するポイントであることを意味します。
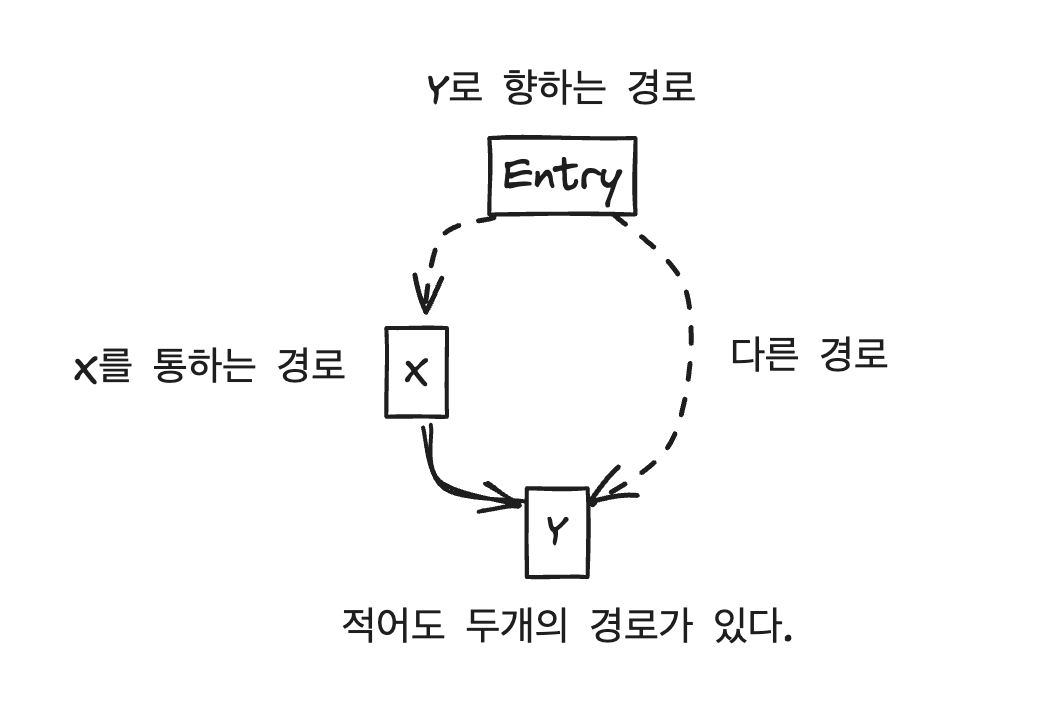
したがってphi関数を分岐が合流するポイント、つまりドミナンスフロンティアDFに置きます。
大体理解できたので、コードで見ていきましょう。
先ほどの例のコードもグラフで表現してみましょうか?
if(condition){
x = 5
} else {
x = 10
}
y = x + 2まずHIR形式で簡単に表現してみましょう。
bb0:
if (condition) goto bb2 else goto bb3
bb2:
x = 5
goto bb1
bb3:
x = 10
goto bb1
bb1:
y = x + 2bb0、bb1、bb2、bb3の4つのブロックに分かれ、CFGとDTグラフを描くと以下のように描かれます。
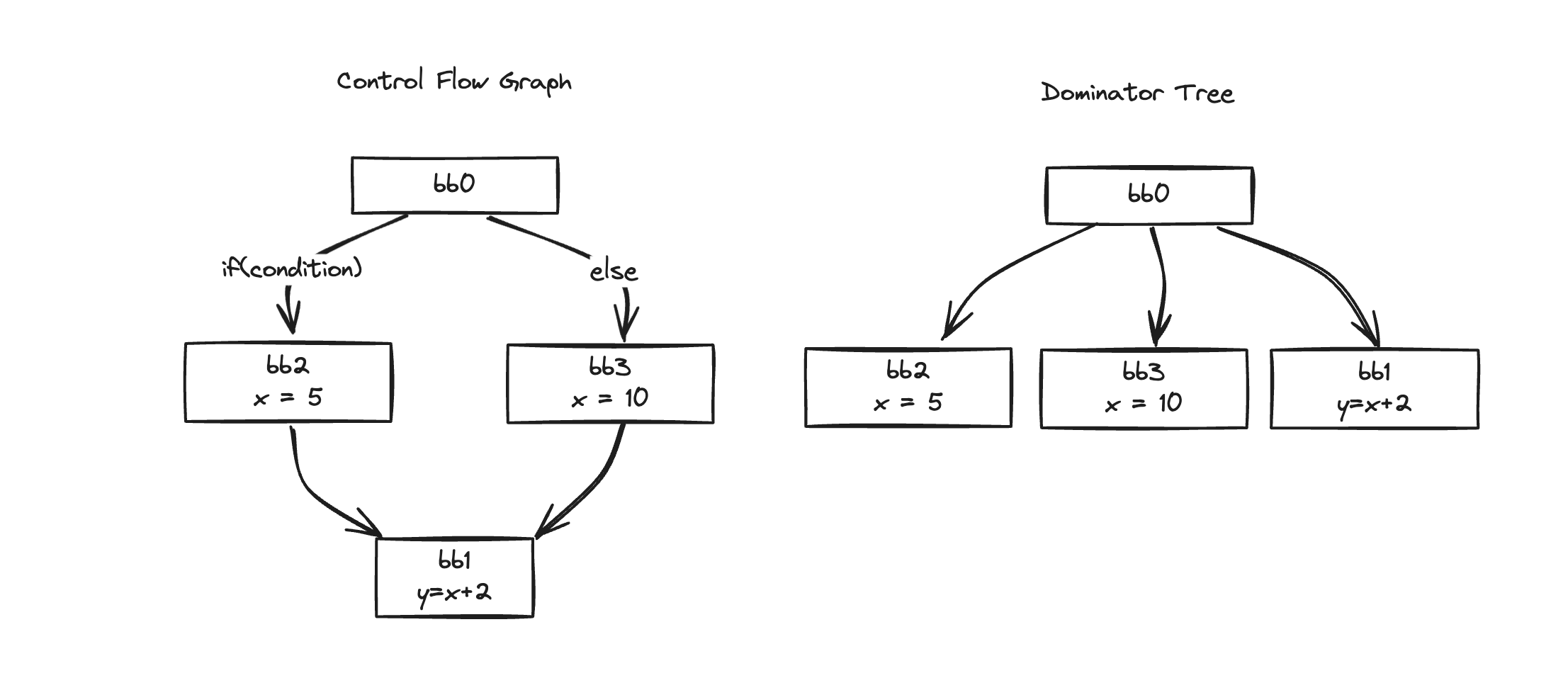
それでは各DFを求めてみましょう。
DF(bb0) = {}
DF(bb2) = {bb1}
DF(bb3) = {bb1}
DF(bb1) = {}DFを見るとbb1一つだけ存在していますね!
それではphi関数はbb1に置くことになります。
上で変換してみたようにy = x + 2があるブロックにphi関数が置かれるわけです。
とても簡単ですよね?
Cytronアルゴリズムはこのような方法でドミネーターツリーとドミナンスフロンティアを通じてphi関数を配置します。
しかし、このアルゴリズムを実行するにはドミネーターツリーを先に作成し、DFを計算するといったプロセスが必要です。
リソースが多くかかると感じませんか?
時が流れて2013年、Braunはこのアルゴリズムを改良した論文を発表します。
Braunのアルゴリズム
Simple and Efficient Construction of Static Single Assignment Form
Matthias Braun1, Sebastian Buchwald1, Sebastian Hack2, Roland Leißa2, Christoph Mallon2, and Andreas Zwinkau
https://pp.ipd.kit.edu/uploads/publikationen/braun13cc.pdfこの論文は2013年にKarlsruhe Institute of TechnologyのMatthias Braunらが発表した論文です。
先ほどのコミットで見たようにReact Compilerで使用されているアルゴリズムです。
Add SSA-ify pass · facebook/react@379251c
The algorithm is described in detail here: https://pp.info.uni-karlsruhe.de/uploads/publikationen/braun13cc.pdf Note that the SSA form generated is not minimal. A follow on RedundantPhiElimina...
https://github.com/facebook/react/commit/379251c65f39039ace1d2e5a80bdb5938cf3427cReact Conf 2024でのQ&Aセッションで、コンパイラ開発のためにMetaがコンパイラの専門家を多く採用したという話がありましたが、
この論文の著者Braunも現在Metaで2018年からコンパイラエンジニアとして働いていることがLinkedInで確認できます。
Matthias Braun
No description available
https://www.linkedin.com/in/matthias-braun-6b5Braunのアルゴリズムは、Cytronのアルゴリズムと比較していくつかの重要な改善点を持っています:
- Cytronのアルゴリズムとは異なり、ドミネーターツリーやドミナンスフロンティアを事前に計算する必要がありません。
- 抽象構文木(AST)やバイトコードから直接SSA形式に変換できます。
- コードを修正するたびにSSA形式を再計算する必要がありません。
Braunのアルゴリズムの主要なステップは以下の通りです:
- ローカル変数番号付け(Local Variable Numbering):単一の基本ブロック内で変数の定義と使用を追跡するプロセスです。主な目的は重複計算を除去しローカルな最適化を実行することです。
- グローバル変数番号付け(Global Variable Numbering):単一の基本ブロックを超えて制御フローグラフ(CFG)全体で変数の定義と使用を追跡するプロセスです。
ローカル変数番号付け(Local Variable Numbering)
function foo() {
let x = 0;
if (x > 3) {
x = 5;
} else {
x = 10;
}
let y = x + 2;
}この例のコードを使って進行過程を見ていきましょう。
途中に条件文があるため、このコードは中間が二つのブロックに分かれます。
そのためHIRに変換すると以下のように変換されます。(今回はコンパイラの中間結果物HIRで見ていきましょう)
function foo
bb0 (block):
[1] $0 = 0
[2] $2 = StoreLocal Let x$1 = $0
[3] $7 = LoadLocal x$1
[4] $8 = 3
[5] $9 = Binary $7 > $8
[6] If ($9) then:bb2 else:bb3 fallthrough=bb1
bb2 (block):
predecessor blocks: bb0
[7] $3 = 5
[8] $4 = StoreLocal Reassign x$1 = $3
[9] Goto bb1
bb3 (block):
predecessor blocks: bb0
[10] $5 = 10
[11] $6 = StoreLocal Reassign x$1 = $5
[12] Goto bb1
bb1 (block):
predecessor blocks: bb2 bb3
[13] $10 = LoadLocal x$1
[14] $11 = 2
[15] $12 = Binary $10 + $11
[16] $14 = StoreLocal Let y$13 = $12
[17] $15 = <undefined>
[18] Return $15分岐前のbb0、ifのthenブロックであるbb2、elseブロックであるbb3、そして分岐後のbb1に分かれていることがわかります。
まず各ブロックに対してローカル変数番号付けを行います。
既存のHIRでは共通してx$1という変数を使用しています。
これを各ブロックに対して新しい変数に変換する必要があります。この時、各変数の定義(def)と使用(use)を追跡します。
定義と使用が同じブロックにある場合、新しいローカル値を番号付けします。
bb0では定義であるStoreLocalと使用であるLoadLocalが同じブロックにあるため、新しいローカル値x_1を番号付けします。
bb2ではStoreLocalとReassignが同じブロックにあるため、ローカル値x_2を番号付けします。
bb3でも同様にローカル値x_3を番号付けします。
bb0のxはx_1、bb2のxはx_2、bb3のxはx_3に変換されます。
function foo
bb0 (block):
[1] $0 = 0
[2] $2 = StoreLocal Let x$1 = $0 // x$1 -> x$1
[3] $7 = LoadLocal x$1
[4] $8 = 3
[5] $9 = Binary $7 > $8
[6] If ($9) then:bb2 else:bb3 fallthrough=bb1
bb2 (block):
predecessor blocks: bb0
[7] $3 = 5
[8] $4 = StoreLocal Reassign x$2 = $3 // x$1 -> x$2
[9] Goto bb1
bb3 (block):
predecessor blocks: bb0
[10] $5 = 10
[11] $6 = StoreLocal Reassign x$3 = $5 // x$1 -> x$3
[12] Goto bb1
bb1 (block):
predecessor blocks: bb2 bb3
[13] $10 = LoadLocal x$1 // x$1 -> ??
[14] $11 = 2
[15] $12 = Binary $10 + $11
[16] $14 = StoreLocal Let y$13 = $12
[17] $15 = <undefined>
[18] Return $15しかしbb1では定義と使用が同じブロックにありません。
定義(def)部分は見当たらず、すぐにLoadLocal(use)があります。
この場合はローカル値を番号付けすることができません。そこで次のステップであるグローバル変数番号付けに進みます。
グローバル変数番号付け(Global Variable Numbering)
グローバル変数番号付けはローカル変数番号付けでのローカルな範囲を超えて、制御フローグラフ(CFG)全体で変数の定義と使用を追跡するプロセスです。
このプロセスを通じてphi関数を置く位置を見つけます。
bb1でのy = x + 2を処理するには、xの値を見つけなければなりません。しかしbb1では定義部分が見当たらないため、以前に遡ってxの値を探す必要があります。
ここからは再帰的にxの定義をたどっていきます。
ブロックの上部を見ると
bb1 (block):
predecessor blocks: bb2 bb3このようなものが見えますね。
このpredecessor(先行者)を通じて前のブロックに遡ります。
predecessorはどうやって見つけることができるでしょうか?
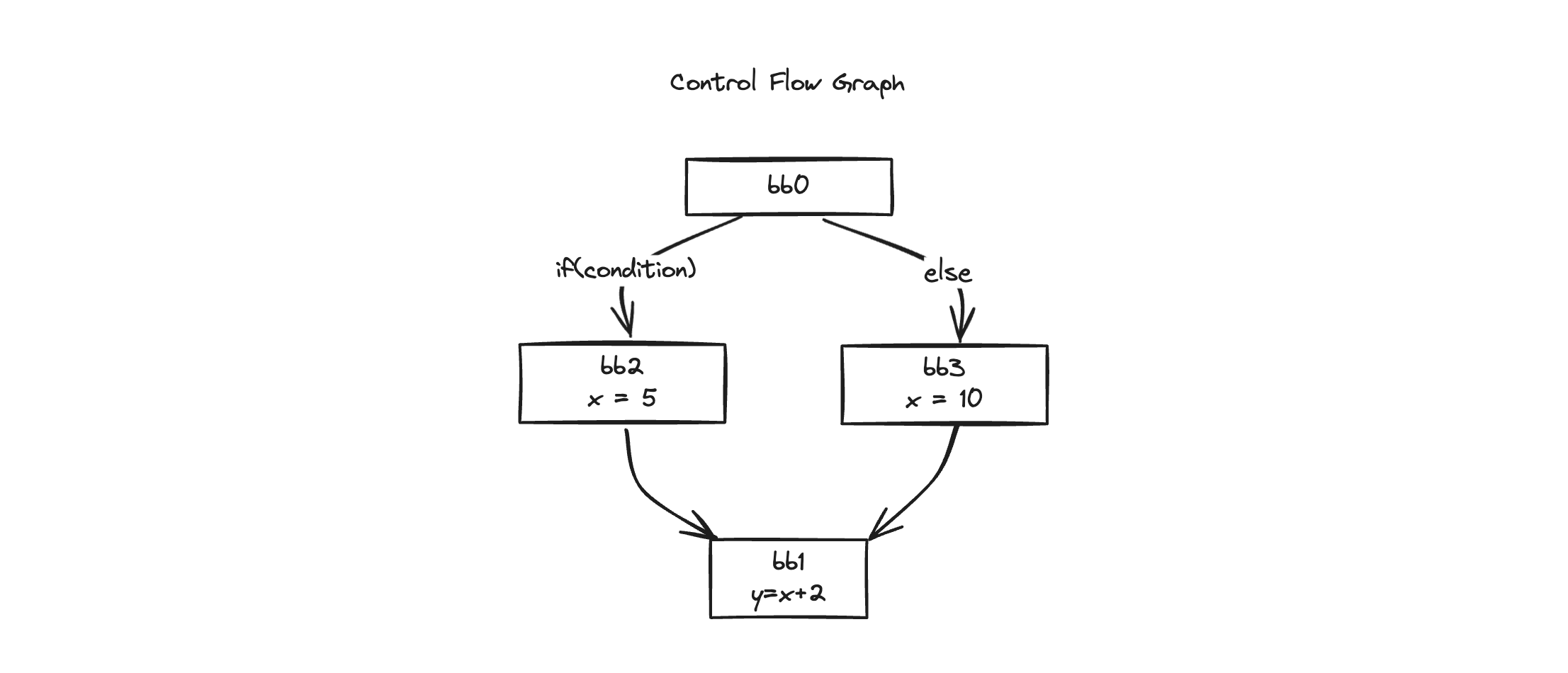
上のグラフで見てわかるように前のブロックがpredecessorになります。
predecessorが一つだけなら、xの定義を前のブロックから簡単に見つけられたでしょう。
しかしbb1の場合はbb2とbb3の二つのpredecessorを持っています。この二つのブロックからxの定義を見つけなければなりません。
それでは各ブロックを見てみましょう。
bb2にはx_2の定義があり、bb3にはx_3の定義があります。
これはbb1が分岐の合流ポイントでもあると見ることができますね!
それでは自信を持ってphi関数をbb1に置いてみましょう。
bb1 (block):
predecessor blocks: bb2 bb3
x$4: phi(bb2: x$2, bb3: x$3) // phi関数を追加
[14] $10 = LoadLocal x$4 // x$1 -> x$4
[15] $11 = 2
[16] $12 = Binary $10 + $11
[17] $14 = StoreLocal Let y$13 = $12
[18] $15 = <undefined>
[19] Return $15このようにphi関数を追加することで、SSA変換の難関の一つだった分岐が合流するポイントにphi関数を置くことに成功しました。
思ったより簡単ですよね?
このプロセス以外にもphi関数の最適化のためのプロセスがまだありますが、ここまで理解できればBraunのアルゴリズムによるSSA変換の核心を理解したことになります。
二つの論文を見ながら、実質的にSSA変換の核心はすべて把握しました。
それではいよいよReact CompilerのSSA変換を見に行きましょう!
React CompilerのSSA変換
前回の記事で見始めたPipeline.tsのrunWithEnvironment関数を再び取り出してみましょう。
// packages/babel-plugin-react-compiler/src/Entrypoint/Pipline.ts
function* runWithEnvironment(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
env: Environment
): Generator<CompilerPipelineValue, CodegenFunction> {
const hir = lower(func, env).unwrap();
// ...
enterSSA(hir);
// ...
}lowerの後いくつかの最適化プロセスを経て、enterSSA関数を通じてHIRをSSAに変換し始めます。
それではenterSSA関数を通じてSSA変換プロセスを見ていきましょう!
export default function enterSSA(func: HIRFunction): void {
const builder = new SSABuilder(func.env, func.body.blocks);
enterSSAImpl(func, builder, func.body.entry);
}前のプロセスで作られたHIRFunctionを使ってSSABuilderを作り、enterSSAImpl関数でSSA変換を開始します。
SSABuilderはさまざまなSSA変換を支援するメソッドを持っています。
詳細なメソッドは変換プロセスを通じて紹介していきましょう。
function enterSSAImpl(
func: HIRFunction,
builder: SSABuilder,
rootEntry: BlockId
): void {
const visitedBlocks: Set<BasicBlock> = new Set();
for (const [blockId, block] of func.body.blocks) {
// ... SSA変換プロセス
}
}enterSSAImpl関数はrootEntryから開始してすべてのブロックを訪問します。
forループでブロックを一つずつ訪問し、その際にSSA変換が行われます。
visitedBlocks Setで始まっていることから、再訪問に対する検証が必要な部分がありそうです。
for (const [blockId, block] of func.body.blocks) {
CompilerError.invariant(!visitedBlocks.has(block), {
reason: `found a cycle! visiting bb${block.id} again`,
description: null,
loc: null,
suggestions: null,
});
visitedBlocks.add(block);
// ...
}すでに訪問したブロックを再度訪問する場合はループが存在する場合なので、エラーとともに終了します。
そうでなければvisitedBlocksに追加してSSA変換を開始します。
初期化
for (const [blockId, block] of func.body.blocks) {
// ...
builder.startBlock(block);
}
// SSABuilder
class SSABuilder {
#states: Map<BasicBlock, State> = new Map();
#current: BasicBlock | null = null;
// ...
startBlock(block: BasicBlock): void {
this.#current = block;
this.#states.set(block, {
defs: new Map(),
incompletePhis: [],
});
}
}startBlockメソッドを通じて現在のブロックとブロックに対するステートをbuilderを通じて初期化します。
パラメータ処理
コンパイラのコンパイル単位は以前見たように関数単位で行われます。
それでは関数の開始部分であるパラメータに対する処理が必要ですよね?
for (const [blockId, block] of func.body.blocks) {
// ...
if (blockId === rootEntry) { // rootEntryの場合
func.params = func.params.map((param) => {
// 一般的なパラメータの場合、foo(a, b, c)のa, b, c
if (param.kind === "Identifier") {
return builder.definePlace(param);
} else {
// Spreadパラメータの場合、foo(...rest)の...rest
return {
kind: "Spread",
place: builder.definePlace(param.place),
};
}
});
}
// ...
}まずrootEntryの場合は関数パラメータをbuilderのdefinePlaceを通じて再度定義します。
class SSABuilder {
// ...
definePlace(oldPlace: Place): Place {
const oldId = oldPlace.identifier;
const newId = this.makeId(oldId);
this.state().defs.set(oldId, newId);
return {
...oldPlace,
identifier: newId,
};
}
// ...
makeId(oldId: Identifier): Identifier {
return {
id: this.nextSsaId,
name: oldId.name,
mutableRange: {
start: makeInstructionId(0),
end: makeInstructionId(0),
},
scope: null, // reset along w the mutable range
type: makeType(),
loc: oldId.loc,
};
}
get nextSsaId(): IdentifierId {
return this.#env.nextIdentifierId;
}
}この時、既存のidentifierをmakeIdメソッドを通じて新しいidentifierに変換します。
idの場合はnextSsaIdというgetterを通じて新しく取得しますが、
グローバル単位で管理されるEnvironmentのnextIdentifierIdを通じて新しいidを取得します。
つまりSSA単位の新しいidを指定するのではなく、グローバルに新しいidが割り当てられるということです。
これまで(loweringプロセスで)10まで使用していたなら、SSA変換を通じて11から新しいidが割り当てられます。
// Environment.ts
makeIdentifierId(id: number): IdentifierId {
return id as IdentifierId;
}
class Environment {
get nextIdentifierId(): IdentifierId {
return makeIdentifierId(this.#nextIdentifer++);
}
}個人的に興味深いテクニックがありました。新しいidをgetterでreturnし、後置インクリメント演算子でidを一つ上げる方式でした。
このようなid管理方法はモーダル管理にも使えそうです。
インストラクション変換
次のプロセスではインストラクションに対する変換を行います。
ここでは例のコードと一緒に変換プロセスを見ていきましょう。
function foo() {
let y = 333;
if (y > 1) {
y = 111;
} else {
y = 222;
}
let x = y;
}このコードをHIR形式に変換すると以下のようになります。
function foo
bb0 (block):
[1] $0 = 333
[2] $2 = StoreLocal Let y$1 = $0
[3] $7 = LoadLocal y$1
[4] $8 = 1
[5] $9 = Binary $7 > $8
[6] If $9) then:bb2 else:bb3 fallthrough=bb1
bb2 (block):
predecessor blocks: bb0
[7] $3 = 111
[8] $4 = StoreLocal Reassign y$1 = $3
[9] Goto bb1
bb3 (block):
predecessor blocks: bb0
[10] $5 = 222
[11] $6 = StoreLocal Reassign y$1 = $5
[12] Goto bb1
bb1 (block):
predecessor blocks: bb2 bb3
[13] $10 = LoadLocal y$1
[14] $12 = StoreLocal Let x$11 = $10
[15] $13 = <undefined>
[16] Return $13bb0~3のblockという単位に分かれ、各ブロックはinstructionとterminalで構成されます。
bb0の場合は以下のように合計5つのInstructionと1つのTerminalで構成されます。
// Instruction
[1] $0 = 333
[2] $2 = StoreLocal Let y$1 = $0
[3] $7 = LoadLocal y$1
[4] $8 = 1
[5] $9 = Binary $7 > $8
// Terminal
[6] If $9) then:bb2 else:bb3 fallthrough=bb1型で見てみるとこのように表現しています。
// HIR.ts
export type BasicBlock = {
kind: BlockKind;
id: BlockId;
instructions: Array<Instruction>; // 命令列
terminal: Terminal; // 終結
preds: Set<BlockId>;
phis: Set<Phi>;
};各命令は以下のような型を持っています。
命令は左辺値(lvalue)= 右辺値(value)の形で構成されています。
export type Instruction = {
id: InstructionId; // 命令の一意識別子
lvalue: Place; // 結果値が格納される位置
value: InstructionValue; // 命令の実際の値/演算
loc: SourceLocation; // 元のソースコードでの位置
};いくつかの命令で確認すると以下のようになります。
// [1] $0 = 333
{
id: 1,
lvalue: {
kind: "Identifier",
identifier: { id: 0, ... }, ...
},
value: { kind: "Primitive", value: 333, ... },
loc,
}
// [2] $2 = StoreLocal Let y$1 = $0
{
id: 2,
lvalue: {
kind: "Identifier",
identifier: { id: 2, ... }, ...
},
value: {
kind: "StoreLocal",
lvalue: {
kind: "Let",
place: {
kind: "Identifier",
identifier: { id: 1, name: { value: "y"}, ... }, ...
},
},
value: {
kind: "Identifier",
identifier: { id: 0, ... }, ...
},
},
}[1]番の命令は最も単純な形で、左辺にはidentifierが、右辺にはPrimitiveが入ります。
[2]番の場合は少し複雑で、左辺にはidentifierが、右辺にはStoreLocalが入ります。
この時、StoreLocalも左辺と右辺で構成されています。
左辺にはLet y$1が入り、右辺にはidentifierが入ります。
それでは変換プロセスを見ていきましょう!
blockのinstructionを一つずつ訪問します。
for (const instr of block.instructions) {
mapInstructionOperands(instr, (place) => builder.getPlace(place));
mapInstructionLValues(instr, (lvalue) => builder.definePlace(lvalue));
// ...
}各instructionに対してmapInstructionOperandsとmapInstructionLValuesを通じてoperandとlvalueを変換します。
operandはinstructionの右辺に該当し、lvalueはinstructionの左辺に該当します。
左辺(LValue)の場合は値が書き込まれる位置なので、上で見た新しいidを割り当てるdefinePlaceを通じて変換します。
右辺(Operands)の場合は値を参照する位置なので、getPlaceを通じて変換します。
どのようなプロセスで値を取得するのかgetPlaceを見てみましょう。
getIdAtを通じてidを取得していますね。それではgetIdAtを見てみましょう。
class SSABuilder {
getPlace(oldPlace: Place): Place {
const newId = this.getIdAt(oldPlace.identifier, this.#current!.id);
return {
...oldPlace,
identifier: newId,
};
}
getIdAt(oldId: Identifier, blockId: BlockId): Identifier {
// check if Place is defined locally
const block = this.#blocks.get(blockId)!;
const state = this.#states.get(block)!;
if (state.defs.has(oldId)) {
return state.defs.get(oldId)!;
}
if (block.preds.size == 0) {
/*
* We're at the entry block and haven't found our defintion yet.
* console.log(
* `Unable to find "${printIdentifier(
* oldId
* )}" in bb${blockId}, assuming it's a global`
* );
*/
this.#unknown.add(oldId);
return oldId;
}
if (this.unsealedPreds.get(block)! > 0) {
/*
* We haven't visited all our predecessors, let's place an incomplete phi
* for now.
*/
const newId = this.makeId(oldId);
state.incompletePhis.push({ oldId, newId });
state.defs.set(oldId, newId);
return newId;
}
// Only one predecessor, let's check there
if (block.preds.size == 1) {
const [pred] = block.preds;
const newId = this.getIdAt(oldId, pred);
state.defs.set(oldId, newId);
return newId;
}
// There are multiple predecessors, we may need a phi.
const newId = this.makeId(oldId);
/*
* Adding a phi may loop back to our block if there is a loop in the CFG. We
* update our defs before adding the phi to terminate the recursion rather than
* looping infinitely.
*/
state.defs.set(oldId, newId);
return this.addPhi(block, oldId, newId);
}
}getIdAtはいくつかのケースに対してidを取得します。
一つずつ見ていきましょう。
- 現在のブロックでoldIdが定義されている場合、そのidを返します。
if (state.defs.has(oldId)) {
return state.defs.get(oldId)!;
}以前definePlaceで新しいidを発行した後、stateのdefsにidのペアを保存していました。
この時oldIdが定義されている場合、そのidを返します。
definePlace(oldPlace: Place): Place {
const oldId = oldPlace.identifier;
const newId = this.makeId(oldId);
this.state().defs.set(oldId, newId); // 新しいidとともに保存
return {
...oldPlace,
identifier: newId,
};
}- エントリーブロックの場合、idが見つからなければグローバルとみなして返します。
if (block.preds.size == 0) {
this.#unknown.add(oldId);
return oldId;
}エントリーブロックの場合はpredsがないためグローバルとみなして返します。
predsはpredecessor(先行者)を意味します。どこかで聞いたことがありませんか?
先ほどBraunのアルゴリズムでpredecessorを通じて前のブロックに遡ることを見ましたよね。
- predecessorが残っている場合、incomplete phiを追加します。
if (this.unsealedPreds.get(block)! > 0) {
const newId = this.makeId(oldId);
state.incompletePhis.push({ oldId, newId });
state.defs.set(oldId, newId);
return newId;
}まだunsealedの概念については見ていないので、一旦スキップします。
- predecessorが一つの場合、predecessorに移動してidを見つけて返します。
if (block.preds.size == 1) {
const [pred] = block.preds;
const newId = this.getIdAt(oldId, pred);
state.defs.set(oldId, newId);
return newId;
}predecessorが一つなら迷う必要なく前のブロックを探索する必要があり、この時再帰的に探索します。
- predecessorが複数の場合、phi関数を追加します。
const newId = this.makeId(oldId);
state.defs.set(oldId, newId);
return this.addPhi(block, oldId, newId);以前見たBraunのアルゴリズムでpredecessorが複数の場合、そのブロックでphi関数を追加することを見ました。
このケースがまさにその実装部分です!
論文で見てきた通りに実装されていますね。
それでは続けてaddPhi関数がどのようにphi関数を追加するか見ていきましょう。
addPhi(block: BasicBlock, oldId: Identifier, newId: Identifier): Identifier {
const predDefs: Map<BlockId, Identifier> = new Map();
for (const predBlockId of block.preds) {
const predId = this.getIdAt(oldId, predBlockId);
predDefs.set(predBlockId, predId);
}
const phi: Phi = {
kind: "Phi",
id: newId,
operands: predDefs,
type: makeType(),
};
block.phis.add(phi);
return newId;
}以前に定義されたものを格納するpredDefsをblockIdとidentifierで構成されたMapとして作成します。
現在のブロックの先行者block.predsを巡回しながら再帰的にgetIdAtを通じてidを見つけてpredDefsに保存します。
そうして得られたpredDefsを通じてphiを作成し、block.phisに追加します。
関数式、オブジェクトメソッドの処理
if (
instr.value.kind === "FunctionExpression" ||
instr.value.kind === "ObjectMethod"
) {
const loweredFunc = instr.value.loweredFunc.func;
const entry = loweredFunc.body.blocks.get(loweredFunc.body.entry)!;
builder.defineFunction(loweredFunc);
builder.enter(() => {
loweredFunc.context = loweredFunc.context.map((p) =>
builder.getPlace(p)
);
loweredFunc.params = loweredFunc.params.map((param) => {
if (param.kind === "Identifier") {
return builder.definePlace(param);
} else {
return {
kind: "Spread",
place: builder.definePlace(param.place),
};
}
});
enterSSAImpl(loweredFunc, builder, rootEntry);
});
}FunctionExpressionとObjectMethodの場合はネストされた関数であるため、再帰的にenterSSAImplを通じて再度SSA変換を行います。
ターミナル処理
mapTerminalOperands(block.terminal, (place) => builder.getPlace(place));terminalの場合は以下のようなケースです。
[6] If $9) then:bb2 else:bb3 fallthrough=bb1 // $9
[9] Goto bb1
[12] Goto bb1
[16] Return $13 // $13このケースで他の要素(13)を参照する場合があるため、idを見つけて変換します。
最終比較
ここまでくるとHIRを構成するすべての要素に対して静的単一代入(SSA)を行ったことになります。 先ほどの例のコードはこのような形に変換されるでしょう。
function foo
bb0 (block):
[1] $14 = 333
[2] $16 = StoreLocal Let y$15 = $14
[3] $17 = LoadLocal y$15
[4] $18 = 1
[5] $19 = Binary $17 > $18
[6] If $19) then:bb2 else:bb3 fallthrough=bb1
bb2 (block):
predecessor blocks: bb0
[7] $20 = 111
[8] $22 = StoreLocal Reassign y$21 = $20
[9] Goto bb1
bb3 (block):
predecessor blocks: bb0
[10] $23 = 222
[11] $25 = StoreLocal Reassign y$24 = $23
[12] Goto bb1
bb1 (block):
predecessor blocks: bb2 bb3
y$26: phi(bb2: y$21, bb3: y$24)
[13] $27 = LoadLocal y$26
[14] $29 = StoreLocal Let x$28 = $27
[15] $30 = <undefined>
[16] Return $30目では比較が難しいのでdiffで比較してみましょう!
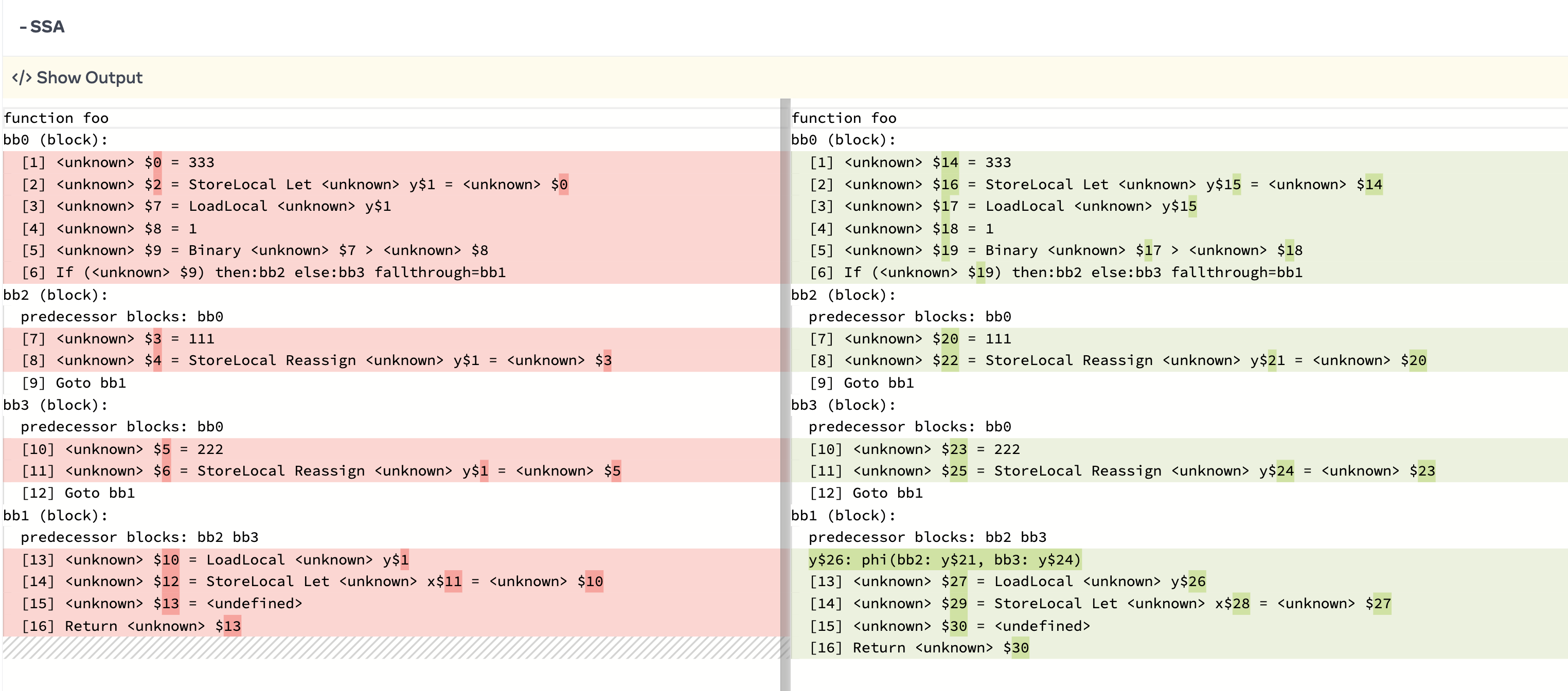
yの値を見ると、すべて個別の値に変換されており、phi関数が追加されていることがわかります。
ループ処理(応用編)
上のプロセスまで見ればSSA変換プロセスがどのようなものか十分理解できるので、スキップしても大丈夫です。
しかしより深く入ってみるとループに対する処理が必要になります。
function foo() {
let x = 1;
for (let i = 0; i < 10; i++) {
x += 1;
}
return x;
}このようなforループがあるコードを見てみましょう。
今まで見てきた条件文のような場合は比較的直感的に上から下への流れでした。
上のブロックからの分岐が下で合流するケースがほとんどでした。
しかしループの場合は再び上に戻るケース(バックエッジ)が生じます。
このような場合はどう処理すればよいでしょうか?
まずHIRに変換してみましょう。
function foo
bb0 (block):
[1] $0 = 1
[2] $2 = StoreLocal Let x$1 = $0
[3] For init=bb3 test=bb1 loop=bb5 update=bb4 fallthrough=bb2
bb3 (loop):
predecessor blocks: bb0
[4] $3 = 0
[5] $5 = StoreLocal Let i$4 = $3
[6] Goto bb1
bb1 (loop):
predecessor blocks: bb3 bb4
[7] $12 = LoadLocal i$4
[8] $13 = 10
[9] $14 = Binary $12 < $13
[10] Branch (<unknown> $14) then:bb5 else:bb2
bb5 (block):
predecessor blocks: bb1
[11] $7 = LoadLocal x$1
[12] $8 = 1
[13] $9 = Binary $7 + $8
[14] $10 = StoreLocal Reassign x$1 = $9
[15] $11 = LoadLocal x$1
[16] Goto(Continue) bb4
bb4 (loop):
predecessor blocks: bb5
[17] $6 = PostfixUpdate i$4 = i$4 ++
[18] Goto bb1
bb2 (block):
predecessor blocks: bb1
[19] $15 = LoadLocal x$1
[20] Return $15理解しやすいようにCFGを描いてみましょう。
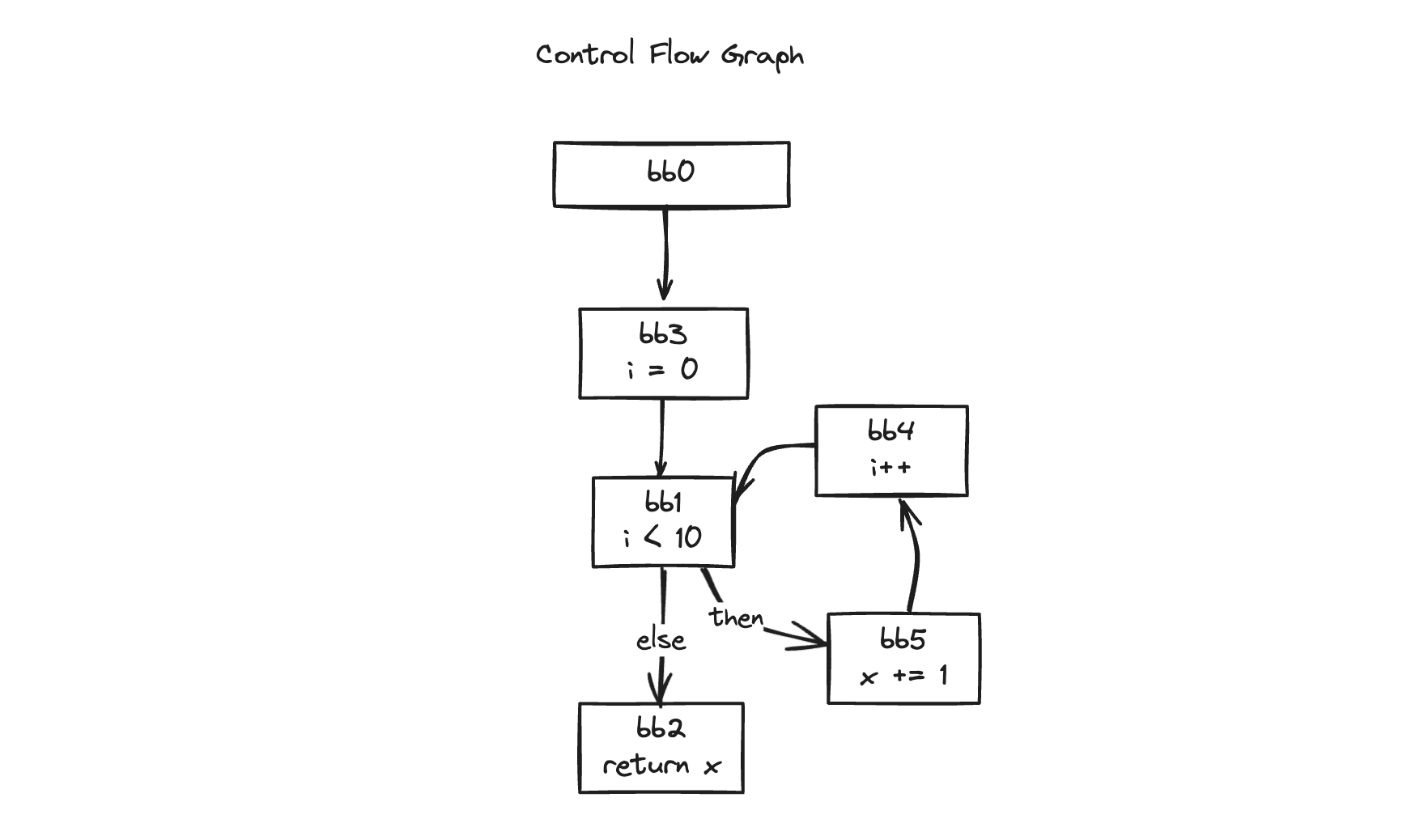
phi関数は分岐が合流するポイントに置けばよかったですよね。
それではbb3、bb4から合流するbb1にphi関数を置けばよさそうです。
ちょうどbb1ブロックを見るとpredecessorも与えられていますね。それでは以前見た再帰的な方法で前のブロックをたどっていけばいいのでしょうか?
しかしこのケースは異なります。
私たちがterminalの処理後にスキップしたプロセスが一つあります。
ターミナルサクセサーに対する処理があります。ターミナル後続ブロックに対する処理です。
ターミナル後続ブロックとは、terminalにIf、Goto、forのような命令がある場合、その命令に対する後続ブロックを意味します。
if文の場合はthen(consequent)、else(alternate)に分かれ、for文の場合はinit、test、loop、updateのような後続ブロックが定義されています。
mapTerminalOperands(block.terminal, (place) => builder.getPlace(place));
for (const outputId of eachTerminalSuccessor(block.terminal)) {
const output = func.body.blocks.get(outputId)!;
let count;
if (builder.unsealedPreds.has(output)) {
count = builder.unsealedPreds.get(output)! - 1;
} else {
count = output.preds.size - 1;
}
builder.unsealedPreds.set(output, count);
if (count === 0 && visitedBlocks.has(output)) {
builder.fixIncompletePhis(output);
}
}後続ブロックに対して、そのブロックの先行者(preds)の数をカウントします。
初めて見るブロックなら先行者の数をcountに入れてunsealedPredsに保存します。
count = output.preds.size - 1;
builder.unsealedPreds.set(output, count);すでに見た後続ブロックなら、先ほどsetしておいたcountからカウントを一つ減らします。
count = builder.unsealedPreds.get(output)! - 1;そのcountが0になり、すでに訪問したブロックなら、すべての先行者を訪問したことを意味します。
この時、fixIncompletePhisを通じてphi関数を追加します。
理解を助けるため、上の例を使ってブロックの順序通りにどのように処理されるか見ていきましょう。
1. bb0
[3] For init=bb3 test=bb1 loop=bb5 update=bb4 fallthrough=bb2bb0の場合、For文の後続ブロックはinitであるbb3になります。
最初のforループが始まる部分なのでinitブロックになります。
export function* eachTerminalSuccessor(terminal: Terminal): Iterable<BlockId> {
switch(terminal.kind){
case "for": {
yield terminal.init;
break;
}
// ...
}
}この時output、後続ブロックであるbb3になり、bb3のpredsはbb0の1つだけなのでcountは0になります。
unsealedPredsに{bb3: 0}が保存されます。
この時visitedBlocksにはbb3がないためfixIncompletePhisは実行されません。
2. bb3
[6] Goto bb1bb3の場合、Goto文の後続ブロックはbb1になります。
bb1のpredsはbb3、bb4なのでcountは1になります。
unsealedPredsを{bb3: 0, bb1: 1}に更新しましょう。
3. bb1
bb1のターミナルを処理する前に、instruction処理のプロセスで分岐に遭遇します。
上で見たgetIdAtを通じてidを処理するプロセスで、先ほどスキップしたこの条件文に遭遇します。
getIdAt(oldId: Identifier, blockId: BlockId): Identifier {
// ...
if (this.unsealedPreds.get(block)! > 0) {
/*
* We haven't visited all our predecessors, let's place an incomplete phi
* for now.
*/
const newId = this.makeId(oldId);
state.incompletePhis.push({ oldId, newId });
state.defs.set(oldId, newId);
return newId;
}
// ...
}この時unsealedPredsでのbb1のcountは1なので、この条件文が真になります。
unsealedな先行ブロックが残っているという意味なので、すぐにphi関数を追加せず、incompletePhisに必要な情報を追加します。
続けてターミナルを処理してみましょう。
[10] Branch (<unknown> $14) then:bb5 else:bb2bb1の場合、Branch文の後続ブロックはthen(consequent):bb5、else(alternate):bb2になります。
case "branch": {
yield terminal.consequent;
yield terminal.alternate;
break;
}順番に処理するとunsealedPredsは{bb3: 0, bb1: 1, bb5: 0, bb2: 0}になります。
両方とも0になりましたが、visitedBlocksにはbb5、bb2がないためfixIncompletePhisは実行されません。
4. bb5
[16] Goto(Continue) bb4bb5の場合、Goto文の後続ブロックはbb4になります。
unsealedPredsは{bb3: 0, bb1: 1, bb5: 0, bb2: 0, bb4: 0}になります。
5. bb4
[18] Goto bb1bb4の場合、Goto文の後続ブロックはbb1になります。
bb1はすでにunsealedPredsにあるため、以前のcountを取得して1を引きます。
unsealedPredsは{bb3: 0, bb1: 0, bb5: 0, bb2: 0, bb4: 0}になります。
この時visitedBlocksにbb1があるためfixIncompletePhisが実行されます。
fixIncompletePhis(block: BasicBlock): void {
const state = this.#states.get(block)!;
for (const phi of state.incompletePhis) {
this.addPhi(block, phi.oldId, phi.newId);
}
}先ほどbb1でincompletePhisに追加しておいたphi関数を追加します。
これによりループに対するphi関数処理まで完了できるようになります。
最後に結果を確認してみましょうか?
function foo
bb0 (block):
[1] $17 = 1
[2] $19 = StoreLocal Let x$18 = $17
[3] For init=bb3 test=bb1 loop=bb5 update=bb4 fallthrough=bb2
bb3 (loop):
predecessor blocks: bb0
[4] $20 = 0
[5] $22 = StoreLocal Let i$21 = $20
[6] Goto bb1
bb1 (loop):
predecessor blocks: bb3 bb4
i$23: phi(bb3: i$21, bb4: i$34) // phi関数が追加された
x$27: phi(bb3: x$18, bb4: x$31) // phi関数が追加された
[7] $24 = LoadLocal i$23
[8] $25 = 10
[9] $26 = Binary $24 < $25
[10] Branch (<unknown> $26) then:bb5 else:bb2
bb5 (block):
predecessor blocks: bb1
[11] $28 = LoadLocal x$27
[12] $29 = 1
[13] $30 = Binary $28 + $29
[14] $32 = StoreLocal Reassign x$31 = $30
[15] $33 = LoadLocal x$31
[16] Goto(Continue) bb4
bb4 (loop):
predecessor blocks: bb5
[17] $35 = PostfixUpdate i$34 = i$23 ++
[18] Goto bb1
bb2 (block):
predecessor blocks: bb1
[19] $36 = LoadLocal x$27
[20] Return $36適切な位置にphi関数が追加されていることが確認できます。
まとめ
今回の記事ではReact CompilerのSSA変換プロセスについて見てきました。
SSA変換は静的単一代入という概念で、変数に対する代入が一度だけ行われることを意味します。
そのプロセスで分岐に対する処理のためにphi関数という概念を導入し、どのようにphi関数を追加するかを見てきました。
これにより変数に対する代入がどこで行われたかを追跡できるようになり、最適化にも役立ちます。
そのプロセスで二つの論文を見てきましたが、
CytronアルゴリズムとBraunアルゴリズムの処理プロセスとそれぞれの長所・短所も見てきました。
そして元々の目的であったReact CompilerのSSA変換プロセスを見てきました。
次回の記事ではこのように変換したSSA形式を通じてどのような最適化を行うのか見ていきます。