これまでのあらすじ
前回の2編を通してコンパイラのエントリーポイントとキャッシュ手法であるuseMemoCacheについて見てきた。 今回からは、コンパイラがどのような過程を経て構文解析とコンパイルを行うのかを見ていこう。
1編で見た、実質的にコンパイルを行う関数であるcompileFnをもう一度見てみよう。
export function compileFn(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
config: EnvironmentConfig,
fnType: ReactFunctionType,
useMemoCacheIdentifier: string,
logger: Logger | null,
filename: string | null,
code: string | null
): CodegenFunction {
let generator = run(
func,
config,
fnType,
useMemoCacheIdentifier,
logger,
filename,
code
);
while (true) {
const next = generator.next();
if (next.done) {
return next.value;
}
}
}compileFn関数はrun関数を通じてコードを生成し、generator.next()でコード生成の過程を繰り返す。
// packages/babel-plugin-react-compiler/src/Entrypoint/Pipline.ts
export type CompilerPipelineValue =
| { kind: "ast"; name: string; value: CodegenFunction }
| { kind: "hir"; name: string; value: HIRFunction }
| { kind: "reactive"; name: string; value: ReactiveFunction }
| { kind: "debug"; name: string; value: string };
export function* run(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
config: EnvironmentConfig,
fnType: ReactFunctionType,
useMemoCacheIdentifier: string,
logger: Logger | null,
filename: string | null,
code: string | null
): Generator<CompilerPipelineValue, CodegenFunction> {
const contextIdentifiers = findContextIdentifiers(func);
const env = new Environment(
fnType,
config,
contextIdentifiers,
logger,
filename,
code,
useMemoCacheIdentifier
);
yield {
kind: "debug",
name: "EnvironmentConfig",
value: prettyFormat(env.config),
};
const ast = yield* runWithEnvironment(func, env);
return ast;
}
run関数はEnvironmentを生成し、runWithEnvironment関数を通じてコードを生成する。
Environmentはコンパイル過程でグローバルな状態と設定を管理するオブジェクトである。
これについての詳細は次回に見ることにして、ひとまず先に進もう。
ではrunWithEnvironment関数を見てみよう。
実質的にコードを生成する関数である。
runWithEnvironment
// packages/babel-plugin-react-compiler/src/Entrypoint/Pipline.ts
function* runWithEnvironment(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
env: Environment
): Generator<CompilerPipelineValue, CodegenFunction> {
const hir = lower(func, env).unwrap();
yield log({ kind: "hir", name: "HIR", value: hir });
pruneMaybeThrows(hir);
yield log({ kind: "hir", name: "PruneMaybeThrows", value: hir });
validateContextVariableLValues(hir);
validateUseMemo(hir);
dropManualMemoization(hir);
yield log({ kind: "hir", name: "DropManualMemoization", value: hir });
// ~~~~~~~~~~~~~~~~~~~~~
// --- 中間の各種過程 ---
// ~~~~~~~~~~~~~~~~~~~~~
const ast = codegenFunction(reactiveFunction, uniqueIdentifiers).unwrap();
yield log({ kind: "ast", name: "Codegen", value: ast });
/**
* This flag should be only set for unit / fixture tests to check
* that Forget correctly handles unexpected errors (e.g. exceptions
* thrown by babel functions or other unexpected exceptions).
*/
if (env.config.throwUnknownException__testonly) {
throw new Error("unexpected error");
}
// 最終的に生成されたコードを返す
return ast;
}全体の過程は約40ほどのステップを経てコードを生成する。
各過程をまず大きく分類すると以下のようになる。
- ‘Lowering’: ASTをHIR(High-level Intermediate Representation)に変換
- ‘Normalization, Optimization’: HIRを正規化し最適化する過程
- ‘Static Analysis, Type Inference’: SSA形式に変換し型推論
- ‘Reactive Optimization’: リアクティブ最適化
- ‘Code Generation’: コード生成
さらに詳細に展開すると以下のようになる。
まだ深く掘り下げずに、どのような過程があるのかだけ眺めてみよう。
-
‘Lowering’
lower: ASTをHIRに変換
-
’最適化および正規化’
pruneMaybeThrows: HIRからMaybeThrowsを除去validateContextVariableLValues: HIRのコンテキスト変数のLValueを検証validateUseMemo: HIRのuseMemoを検証dropManualMemoization: 手動メモ化を除去inlineImmediatelyInvokedFunctionExpressions: 即時実行関数式(IIFE)のインライン化mergeConsecutiveBlocks: 連続するブロックの結合
-
’静的解析および型推論’
enterSSA: SSA(Static Single Assignment)形式に変換eliminateRedundantPhi: 冗長なPhiノードの除去constantPropagation: 定数伝播inferTypes: 型推論validateHooksUsage: フック使用の妥当性検査validateNoCapitalizedCalls: 大文字で始まる関数呼び出しの検査analyseFunctions: 関数分析inferReferenceEffects: 参照エフェクトの推論deadCodeElimination: デッドコードの除去inferMutableRanges: ミュータブル範囲の推論inferReactivePlaces: リアクティブプレースの推論leaveSSA: SSA形式から通常の形式に復帰
-
’リアクティブ最適化(HIR)’
inferReactiveScopeVariables: リアクティブスコープ変数の推論alignMethodCallScopes: メソッド呼び出しスコープの整列alignObjectMethodScopes: オブジェクトメソッドスコープの整列memoizeFbtOperandsInSameScope: 同一スコープ内のFbtオペランドのメモ化pruneUnusedLabelsHIR: 未使用ラベルの除去alignReactiveScopesToBlockScopesHIR: リアクティブスコープのブロックスコープへの整列mergeOverlappingReactiveScopesHIR: 重複するリアクティブスコープの結合buildReactiveScopeTerminalsHIR: リアクティブスコープターミナルの生成buildReactiveFunction: リアクティブ関数の生成
-
’リアクティブ最適化(Reactive function)’
pruneUnusedLabels: 未使用ラベルの除去flattenReactiveLoops: リアクティブループの平坦化propagateScopeDependencies: スコープ依存関係の伝播pruneNonReactiveDependencies: 非リアクティブ依存関係の除去pruneUnusedScopes: 未使用スコープの除去mergeReactiveScopesThatInvalidateTogether: 同時に無効化されるリアクティブスコープの結合pruneAlwaysInvalidatingScopes: 常に無効化されるスコープの除去propagateEarlyReturns: 早期リターンの伝播promoteUsedTemporaries: 使用済み一時変数のプロモーションpruneUnusedLValues: 未使用LValueの除去extractScopeDeclarationsFromDestructuring: 分割代入からのスコープ宣言の抽出stabilizeBlockIds: ブロックIDの安定化renameVariables: 変数のリネームpruneHoistedContexts: ホイスティングされたコンテキストの除去
-
’Code Generation’
codegenFunction: 最終コード生成
すべての過程を見ていくかは分からないが、まずは始めてみよう。
Lowering
const hir = lower(func, env).unwrap();React Compilerの最初のステップであるLoweringは、AST(Abstract Syntax Tree)をHIR(High-level Intermediate Representation)に変換する過程である。
まずコンパイルについて改めておさらいしよう。
to collect information from different places and arrange it in a book, report, or list
[Cambridge Dictionary]
辞書的な意味では、さまざまな情報を収集して書籍、レポート、またはリストにまとめることを意味する。
コンピュータサイエンスにおいてコンパイルとは、ソースコードを機械語に変換する過程を意味する。
機械語に変換する。簡単に言えば、コンピュータが理解できる言語に変換するということだ。
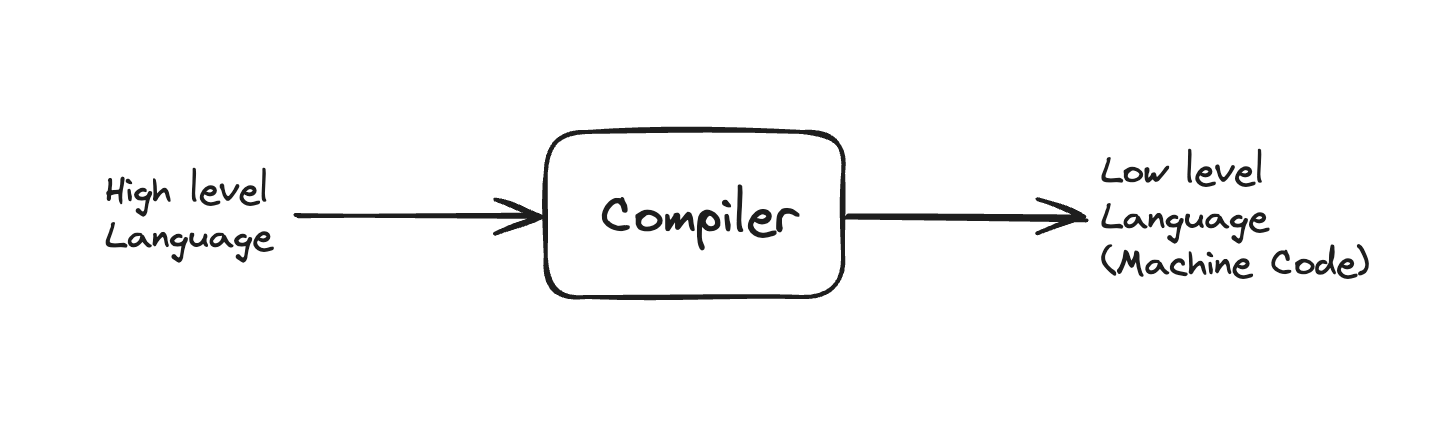
ソースコードからBabelによってASTに変換され、このASTをもう一段階低くして中間表現(IR)に変換したため、Loweringと呼ばれる。
それでは、HIRに変換するlower関数を見てみよう。
// packages/babel-plugin-react-compiler/src/HIR/BuildHIR.ts
/*
* 関数を制御フローグラフ(Control-Flow Graph, CFG)で表す高水準中間表現(HIR)に変換します。
* すべての正常な制御フローは正確にモデリングされ、正確な式レベル(expression-level)のメモ化を可能にします。
* 主な例外はtry/catch文と例外です。
* 現在、try/catchのためにコンパイルをスキップし、例外の制御フローをモデリングしようとしません。
* これはJavaScriptのどこでも発生しうる例外です。
* コンパイラは例外がランタイムによって処理されることを前提としており、
* つまりメモ化を無効化することで処理されることを前提としています。
*/
export function lower(
func: NodePath<t.Function>,
env: Environment,
bindings: Bindings | null = null,
capturedRefs: Array<t.Identifier> = [],
// 再帰的に呼び出される場合(ラムダ関数の場合)lower()を呼び出す最も外側の関数
parent: NodePath<t.Function> | null = null
): Result<HIRFunction, CompilerError> {
// ...
}関数の上のコメントを参考にすると、AST(Abstract Syntax Tree)をCFG(Control-Flow Graph、以下CFG)で表す高水準中間表現(HIR)に変換するとある。
ASTは構文木で、プログラムの構文を表すツリー形式のデータ構造であるのに対し、CFGは制御フローグラフで、プログラムの制御フローを表すグラフ形式のデータ構造である。
グラフの各ノードは基本ブロック(Basic Block)と呼ばれるコードの連続的な部分を表し、エッジ(edge)は一つの基本ブロックから別の基本ブロックへの制御フローを表す。
制御フロー構造とは、if/else、switch、loopのような分岐と繰り返しを意味する。
CFGはプログラムのすべての可能な実行パスを捉え、コードの最適化と分析に使用される。
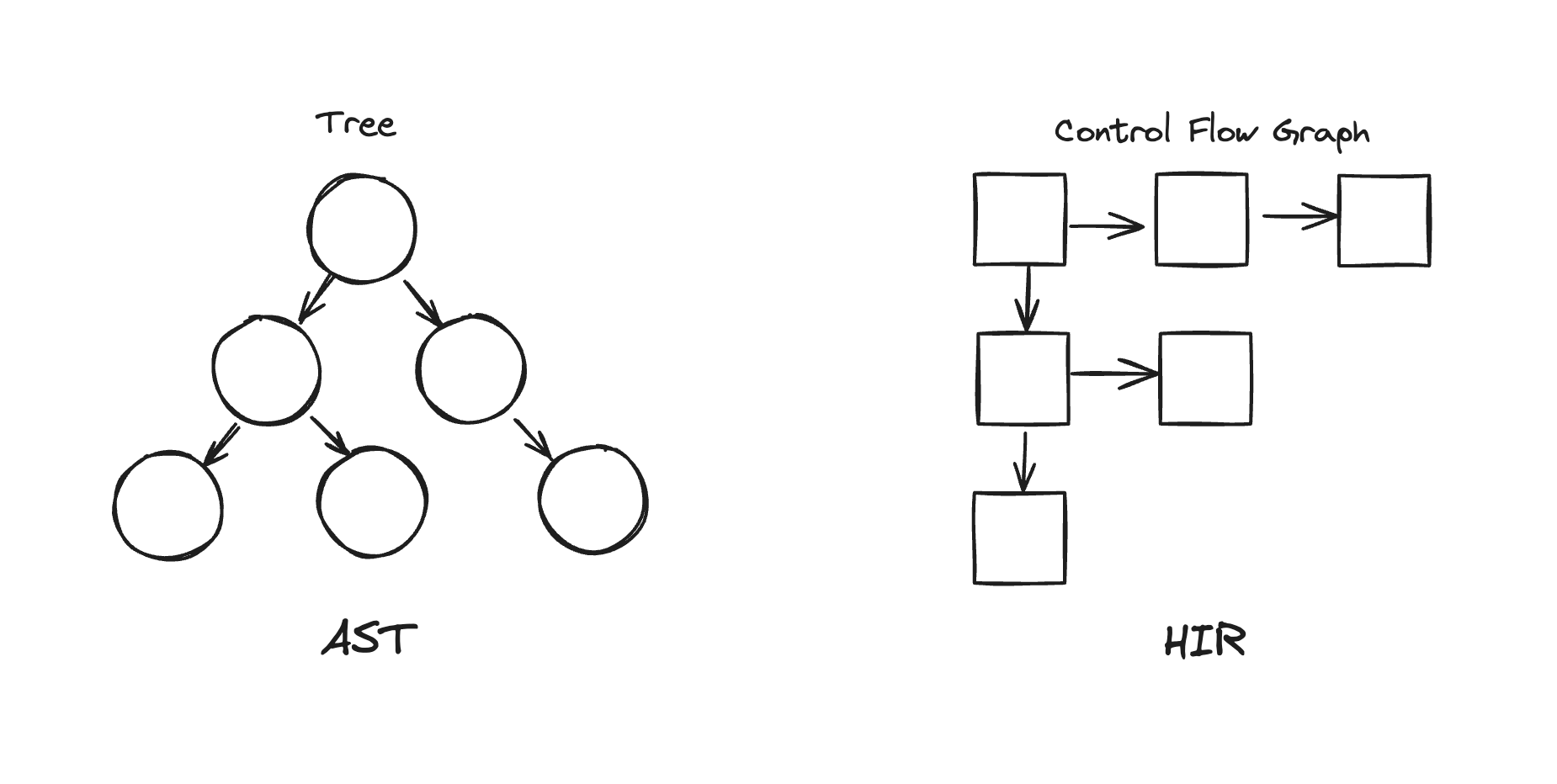
図はこのように描いたが、各ノードは互いにマッチしない。
理解を助けるために、まず出力結果を見てみよう。
以下は簡単なコードをASTとHIRに変換した結果である。
function Component({ color }: { color: string }) {
if (color === "red") {
return (<div styles={{ color }}>hello red</div>)
} else {
return (<div styles={{ color }}>hello etc</div>)
}
}理解を助けるためのサンプルコードだ。Component関数はcolorがredの場合とそうでない場合で異なるJSXを返す。
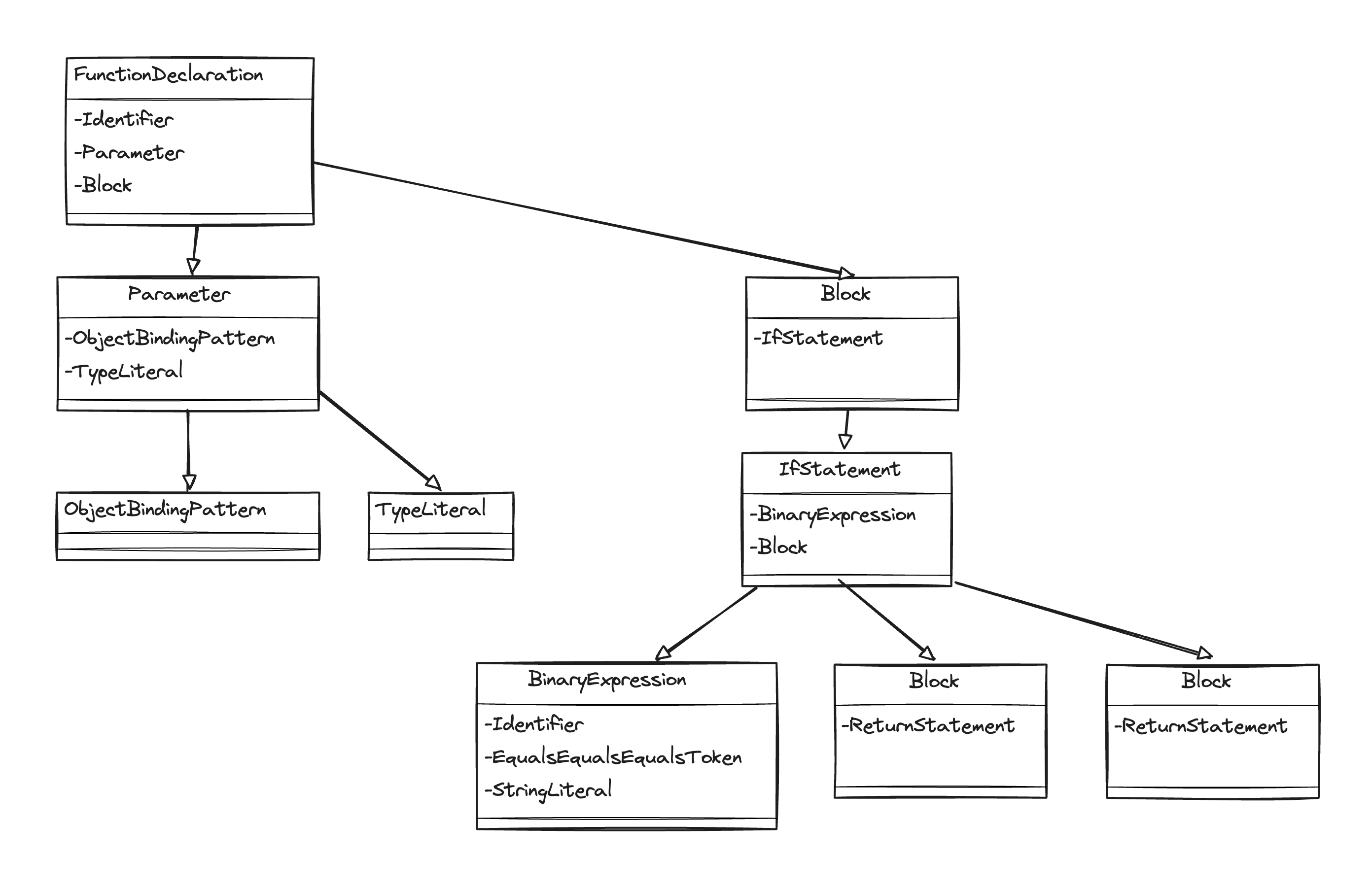
このコードをASTで表すと、以下のような構文のツリーとして表現される。
// Component 関数
FunctionDeclaration
Identifier
Parameter
ObjectBindingPattern
BindingElement
Identifier
TypeLiteral
Block
IfStatement
BinaryExpression
Identifier
EqualsEqualsEqualsToken
StringLiteral
Block
ReturnStatement
ParenthesizedExpression
JsxElement
JsxOpeningElement
Identifier
//...
//...グラフで表すと以下のようになる。
このASTをHIRに変換すると、以下のような結果が得られる。
function Component
bb0 (block):
[1] <unknown> $2 = Destructure Let { color: <unknown> color$1 } = <unknown> $0
[2] <unknown> $11 = LoadLocal <unknown> color$1
[3] <unknown> $12 = "red"
[4] <unknown> $13 = Binary <unknown> $11 === <unknown> $12
[5] If (<unknown> $13) then:bb2 else:bb4 fallthrough=bb1
bb2 (block):
predecessor blocks: bb0
[6] <unknown> $3 = LoadLocal <unknown> color$1
[7] <unknown> $4 = Object { color: <unknown> $3 }
[8] <unknown> $5 = JSXText "hello red"
[9] <unknown> $6 = JSX <div styles={<unknown> $4} >{<unknown> $5}</div>
[10] Return <unknown> $6
bb4 (block):
predecessor blocks: bb0
[11] <unknown> $7 = LoadLocal <unknown> color$1
[12] <unknown> $8 = Object { color: <unknown> $7 }
[13] <unknown> $9 = JSXText "hello etc"
[14] <unknown> $10 = JSX <div styles={<unknown> $8} >{<unknown> $9}</div>
[15] Return <unknown> $10
bb1 (block):
[16] Unreachableここでコードを理解しなくても大丈夫だ。ざっと眺めるだけでいい。
このサンプルコードにおける制御フローはComponent関数内のif文である。それに応じてComponent関数はbb0、bb2、bb4、そしてbb1の4つの基本ブロックに分割された。
[5] If (<unknown> $13) then:bb2 else:bb4 fallthrough=bb1この部分を見ると、If文によってbb2に行く場合とbb4に行く場合、そしてfallthroughでbb1に行くフローが表現されている。
fallthroughはif文を通過した後のフローを表す。この場合は到達不可能なコードとして表示されている。
理解を助けるために図を描くと、以下のようになる。
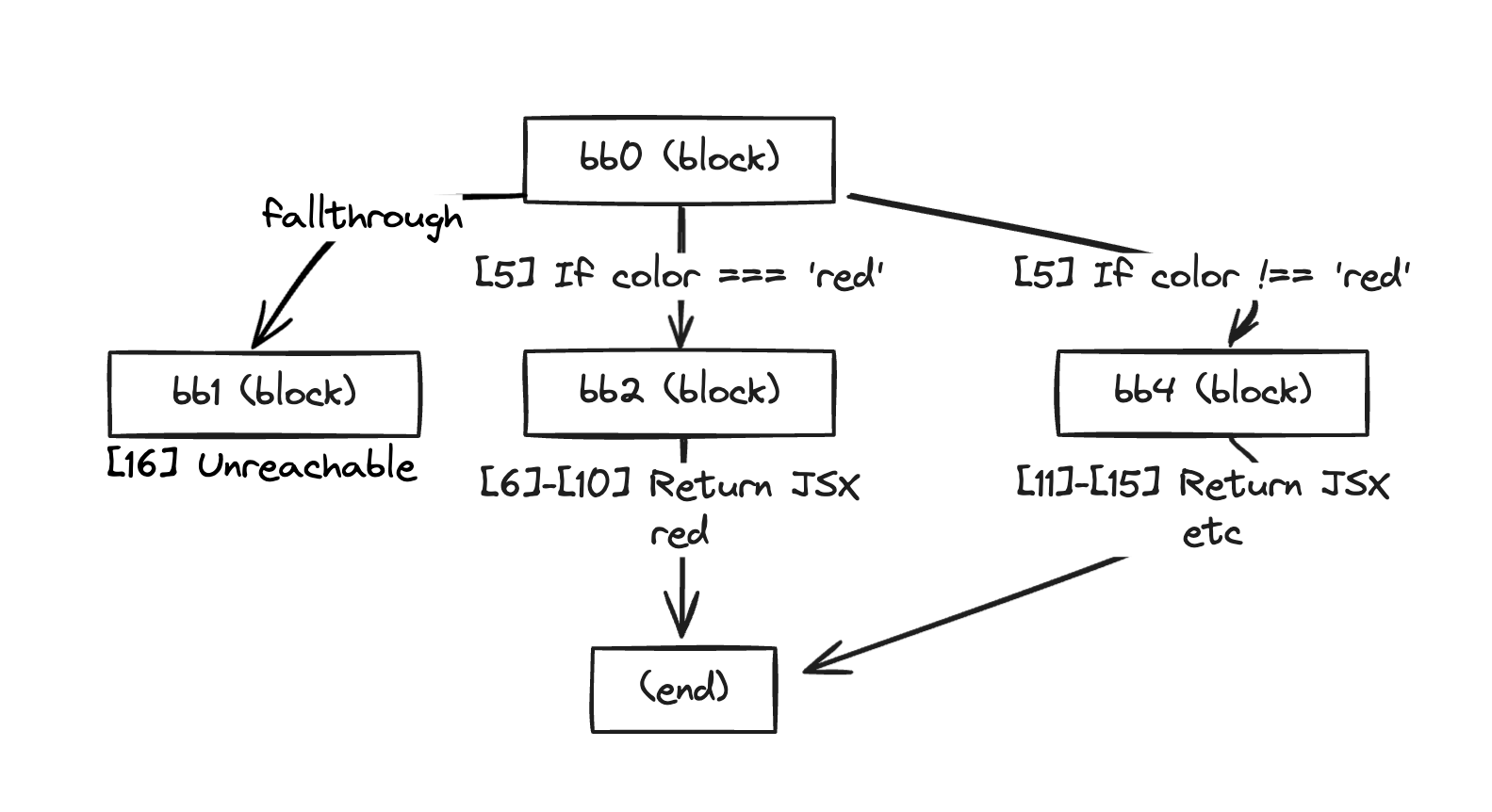
なるほど、どのような形に変換されるかイメージが掴めてきた。
構文単位のツリーをこのような形の制御フローに基づくグラフで表現するための変換過程がLoweringなのだ。
そして、その変換された表現形式をHIRと呼ぶ。(React Compilerにおいて)
途中下車地点
ここまで見るだけでも、HIRがどのようなデータ構造を意味するか大まかに分かるので、コンパイル過程を理解する上では問題ないだろう。
なので、次の編にそのまま進んでも構わない。
Detach!
再びlower関数へ
ここから先は純粋な知的好奇心からLoweringの過程を見ていくことにする。すべての構文に対するLowering処理が含まれているため、コード自体は約4,000行ほどある。
では、じっくり見ていこう。
再び最初に戻ってlower関数を見てみよう。
export function lower(
func: NodePath<t.Function>,
env: Environment,
bindings: Bindings | null = null,
capturedRefs: Array<t.Identifier> = [],
// the outermost function being compiled, in case lower() is called recursively (for lambdas)
parent: NodePath<t.Function> | null = null
): Result<HIRFunction, CompilerError> {}lower関数はBabelに由来するNodePath<t.Function>を入力として受け取り、HIRFunctionを返す。(エラーが発生した場合はCompilerErrorを返す。)
その他の引数としては、Environmentオブジェクト、Bindings、capturedRefs、parentなどがある。
このとき入力として渡されるfuncの単位は何か?
以前の1編で見た内容を思い出してみよう。
programノードのtraverseメソッドで巡回しながら関数に対するノードを見つけ出し、そのノードをcompileFn関数に渡していた。
そのためfuncはBabel ASTから渡される関数に対するノードになる。
FunctionDeclaration、FunctionExpression、ArrowFunctionExpressionがそれに該当する。
続いて…
const builder = new HIRBuilder(env, parent ?? func, bindings, capturedRefs);
const context: Array<Place> = [];HIRBuilderインスタンスを生成して変数に格納し、context配列を初期化する。関数のコンテキスト情報を格納する配列だ。
for (const ref of capturedRefs ?? []) {
context.push({
kind: "Identifier",
identifier: builder.resolveBinding(ref),
effect: Effect.Unknown,
reactive: false,
loc: ref.loc ?? GeneratedSource,
});
}capturedRefs配列を巡回しながら、context配列にPlaceオブジェクトを追加する。
この部分は再帰呼び出しの場合なので、後で改めて見ることにして、ひとまず先に進もう。
関数名の抽出(識別子、Identifier)
関数がFunctionDeclarationまたはFunctionExpressionの場合、関数のid(Identifier)識別子を取得してid変数に代入する。
let id: string | null = null;
if (func.isFunctionDeclaration() || func.isFunctionExpression()) {
const idNode = (
func as NodePath<t.FunctionDeclaration | t.FunctionExpression>
).get("id");
if (hasNode(idNode)) {
id = idNode.node.name;
}
}FunctionDeclaration(関数宣言式)ノードとFunctionExpression(関数式)ノードは 識別子を持つことができるが、ArrowFunctionExpression(アロー関数)ノードは識別子を持つことができない。
// FunctionDeclaration
function foo() {}
// FunctionExpression
const foo = function bar() {}
// ArrowFunctionExpression
const foo = () => {}引数の抽出(Parameters)
関数の引数を抽出し、params配列にPlaceオブジェクトを追加する。
params: Array<Identifier | Pattern | RestElement> (required)paramsにはIdentifier、Pattern、RestElementが入る可能性がある。
Identifierは識別子、Patternはオブジェクトや配列パターン、RestElementは残余要素を表す。
const params: Array<Place | SpreadPattern> = [];
func.get("params").forEach((param) => {
if (param.isIdentifier()) {}
else if (param.isObjectPattern() || param.isArrayPattern() || param.isAssignmentPattern()) {}
else if (param.isRestElement()) {}
else {}
// ...
});Identifier(単一変数名)
// 例
const greet = function(name) { // nameがIdentifier
console.log(`Hello, ${name}!`);
};引数がIdentifierの場合、Placeオブジェクトを生成してparams配列に追加する。
if (param.isIdentifier()) {
const binding = builder.resolveIdentifier(param);
const place: Place = {
kind: "Identifier",
identifier: binding.identifier,
effect: Effect.Unknown,
reactive: false,
loc: param.node.loc ?? GeneratedSource,
};
params.push(place);
}今後頻繁に登場するが、Placeオブジェクトは以下のように定義されている。
/*
* データの読み書きが可能な場所:
* - 変数(識別子)
* - 識別子へのパス
*/
export type Place = {
kind: "Identifier"; // 種類
identifier: Identifier; // 識別子
effect: Effect; // The effect with which a value is modified. (値が変更される際のエフェクト)
reactive: boolean;
loc: SourceLocation;
};ObjectPattern(オブジェクトパターン)、ArrayPattern(配列パターン)、AssignmentPattern(代入パターン)
// 例
// ObjectPattern
const greet = function({ name }) {
console.log(`Hello, ${name}!`);
};
// ArrayPattern
const greet = function([name]) {
console.log(`Hello, ${name}!`);
};
// AssignmentPattern
const greet = function(name = 'world') {
console.log(`Hello, ${name}!`);
};
引数がObjectPattern、ArrayPattern、AssignmentPatternの場合、一時変数を生成してPlaceオブジェクトを作成し、params配列に追加する。
lowerAssignment関数を通じて代入を処理する。
else if (
param.isObjectPattern() ||
param.isArrayPattern() ||
param.isAssignmentPattern()
) {
const place: Place = {
kind: "Identifier",
identifier: builder.makeTemporary(),
effect: Effect.Unknown,
reactive: false,
loc: param.node.loc ?? GeneratedSource,
};
params.push(place);
lowerAssignment(
builder,
param.node.loc ?? GeneratedSource,
InstructionKind.Let,
param,
place,
"Assignment"
);
}RestElement(残余要素)
// 例
const greet = function(...names) {
console.log(`Hello, ${names.join(', ')}!`);
};引数がRestElementの場合、一時変数を生成してSpreadオブジェクトを作成し、params配列に追加する。
else if (param.isRestElement()) {
const place: Place = {
kind: "Identifier",
identifier: builder.makeTemporary(),
effect: Effect.Unknown,
reactive: false,
loc: param.node.loc ?? GeneratedSource,
};
params.push({
kind: "Spread",
place,
});
lowerAssignment(
builder,
param.node.loc ?? GeneratedSource,
InstructionKind.Let,
param.get("argument"),
place,
"Assignment"
);
}このようにして関数の引数を抽出し、params配列にPlaceオブジェクトを追加する過程を経る。
では、関数の本体を抽出してbody配列にInstructionオブジェクトを追加する過程を見てみよう。
関数本体の抽出(Body)
let directives: Array<string> = [];
const body = func.get("body");関数の本体を抽出し、directives配列を初期化する。
Expression(式)
if (body.isExpression()) {
const fallthrough = builder.reserve("block");
const terminal: ReturnTerminal = {
kind: "return",
loc: GeneratedSource,
value: lowerExpressionToTemporary(builder, body),
id: makeInstructionId(0),
};
builder.terminateWithContinuation(terminal, fallthrough);
}BlockStatement(ブロック文)
ブロック文の場合、lowerStatement関数を通じてbodyを処理する。
else if (body.isBlockStatement()) {
lowerStatement(builder, body);
directives = body.get("directives").map((d) => d.node.value.value);
}この部分が実質的にコアな部分と言える。
lowerStatement関数を見てみよう。
function lowerStatement(
builder: HIRBuilder,
stmtPath: NodePath<t.Statement>,
label: string | null = null
): void {
const stmtNode = stmtPath.node;
switch (stmtNode.type) {
case "ThrowStatement":
case "ReturnStatement":
case "IfStatement":
case "BlockStatement":
case "BreakStatement":
case "ContinueStatement":
case "ForStatement":
case "WhileStatement":
case "LabeledStatement":
case "SwitchStatement":
case "VariableDeclaration":
case "ExpressionStatement":
case "DoWhileStatement":
case "FunctionDeclaration":
case "ForOfStatement":
case "ForInStatement":
case "DebuggerStatement":
case "EmptyStatement":
case "TryStatement":
// ------- skip -------
case "TypeAlias":
case "TSTypeAliasDeclaration":
// --- unsupported ---
case "ClassDeclaration":
// ~
case "WithStatement":
default:stmtPath(Statement Path)のノードタイプに応じてさまざまな処理を行う。
lower関数から呼び出される際、stmtPathにはBlockStatementが渡される。では、例を通じて見てみよう。
// 例
function complexExample(x) {
let result = 0;
if (x > 0) {
result = x * 2;
} else {
result = x * 3;
}
return result;
}関数complexExampleのbodyはBlockStatementだ。このBlockStatementをlowerStatement関数に渡してみよう。
case "BlockStatement": {
const stmt = stmtPath as NodePath<t.BlockStatement>;
const statements = stmt.get("body");stmtPathをBlockStatementにキャストし、bodyを抽出する。
bodyはNodePath<t.Statement>[]型で、ブロック文内の各文を表す。
for (const s of statements) {
lowerStatement(builder, s);
}statementsを巡回しながら、lowerStatement関数を再帰的に呼び出す。
BlockStatementの処理中の再帰的な処理以外にも、もう一つの過程がある。
‘const’変数宣言のホイスティング処理
まず、あるバインディングが宣言される前に参照された場合にホイスティング可能かどうかを確認し、
該当する宣言を参照される最も早い地点(つまり、直前の最上位の文)にコンテキスト変数としてホイスティングする。
const hoistableIdentifiers: Set<t.Identifier> = new Set();
for (const [, binding] of Object.entries(stmt.scope.bindings)) {
// refs to params are always valid / never need to be hoisted
if (binding.kind !== "param") {
hoistableIdentifiers.add(binding.identifier);
}
}hoistableIdentifiersというSetを生成し、stmt.scope.bindingsを巡回しながら
identifierをhoistableIdentifiersに追加する。
stmt.scope.bindingsは現在のブロックのバインディング情報を保持している。
親や子ブロックのバインディング情報は含まれない。
このとき、const、let、varがhoistableIdentifiersに追加される。
各文を巡回する際に、ホイスティングが必要な要素を格納するwillHoistというSetを生成する。
for (const s of statements) {
const willHoist = new Set<NodePath<t.Identifier>>();
// ...
}関数コンテキストの深さを追跡する。識別子の参照が内部関数で発生しているかを追跡するためだ。
traverseで探索しながらFunctionExpression、FunctionDeclaration、ArrowFunctionExpression、ObjectMethodノードに遭遇すると関数の深さを増加させ、ノードを抜ける際に関数の深さを減少させる。
let fnDepth = s.isFunctionDeclaration() ? 1 : 0;
const withFunctionContext = {
enter: (): void => {
fnDepth++; // 関数の深さを増加
},
exit: (): void => {
fnDepth--; // 関数の深さを減少
},
};
s.traverse({
FunctionExpression: withFunctionContext, // 関数式
FunctionDeclaration: withFunctionContext, // 関数宣言式
ArrowFunctionExpression: withFunctionContext, // アロー関数
ObjectMethod: withFunctionContext, // オブジェクトメソッド
// ...
});文を巡回しながら識別子を探す。
識別子が参照されていないか、親が代入式でない場合はスキップする。
識別子が参照されておりhoistableIdentifiersに存在し、関数の深さが0より大きいかバインディングがhoistedの場合、willHoistに追加する。
s.traverse({
// ...
Identifier(id: NodePath<t.Identifier>) {
const id2 = id;
if (
!id2.isReferencedIdentifier() &&
// isReferencedIdentifier is broken and returns false for reassignments
id.parent.type !== "AssignmentExpression"
) {
return;
}
const binding = id.scope.getBinding(id.node.name);
/*
* 識別子の宣言をホイスティングできるケースは以下の通りです。
* 1. 参照が内部関数内で発生する場合
* または
* 2. 宣言自体がホイスティング可能な場合
*/
if (
binding != null &&
hoistableIdentifiers.has(binding.identifier) &&
(fnDepth > 0 || binding.kind === "hoisted")
) {
willHoist.add(id);
}
},
});その後、再びノードを巡回しながらhoistableIdentifiersにある識別子を削除する。
s.traverse({
Identifier(path: NodePath<t.Identifier>) {
if (hoistableIdentifiers.has(path.node)) {
hoistableIdentifiers.delete(path.node);
}
},
});willHoistを巡回しながら、identifierをresolveIdentifierを通じてユニークな識別子に変換し、
lowerValueToTemporary関数を通じて一時変数にDeclareContextを生成してbuilderにpushする。
その後、グローバル環境の#contextIdentifiers、#hoistedIdentifiersに追加する。
// Hoist declarations that need it to the earliest point where they are needed
for (const id of willHoist) {
const binding = stmt.scope.getBinding(id.node.name);
if (builder.environment.isHoistedIdentifier(binding.identifier)) {
// Already hoisted
continue;
}
const identifier = builder.resolveIdentifier(id);
const place: Place = {
effect: Effect.Unknown,
identifier: identifier.identifier,
kind: "Identifier",
reactive: false,
loc: id.node.loc ?? GeneratedSource,
};
lowerValueToTemporary(builder, {
kind: "DeclareContext",
lvalue: {
kind: InstructionKind.HoistedConst,
place,
},
loc: id.node.loc ?? GeneratedSource,
});
builder.environment.addHoistedIdentifier(binding.identifier);後にコード生成前にDeclareContextを除去し、関連するStoreContextを再変換して元のソースコードを復元する。
他の種類の宣言に対するホイスティングは今後実装予定である。
ホイスティング(Hoisting)をする理由は?
しかし、今回見たのはコンパイラが行うホイスティングだ。
constのホイスティングをする理由は何だろうか?例とともに見てみよう。テストコードを通じて見ると良質な例が得られる。/src/__tests__/fixtures/compilerに移動してみよう。
簡潔に見えるコードを一つ拾ってきた。“hoisting-simple-const-declaration.expected.md”ファイルを開いてみよう。
function hoisting() {
const foo = () => {
return bar + baz;
};
const bar = 3;
const baz = 2;
return foo(); // OK: called outside of TDZ for bar/baz
}シンプルなホイスティングの例だ。これをHIRに変換すると以下のようになる。
function hoisting
bb0 (block):
[1] <unknown> $1 = DeclareContext HoistedConst <unknown> bar$0
[2] <unknown> $3 = DeclareContext HoistedConst <unknown> baz$2
[3] <unknown> $4 = LoadContext <unknown> bar$0
[4] <unknown> $5 = LoadContext <unknown> baz$2
[5] <unknown> $10 = Function @deps[<unknown> $4,<unknown> $5] @context[<unknown> bar$0,<unknown> baz$2] @effects[]:
bb1 (block):
[1] <unknown> $6 = LoadContext <unknown> bar$0
[2] <unknown> $7 = LoadContext <unknown> baz$2
[3] <unknown> $8 = Binary <unknown> $6 + <unknown> $7
[4] Return <unknown> $8
[6] <unknown> $12 = StoreLocal Const <unknown> foo$11 = <unknown> $10
[7] <unknown> $13 = 3
[8] <unknown> $14 = StoreContext Reassign <unknown> bar$0 = <unknown> $13
[9] <unknown> $15 = 2
[10] <unknown> $16 = StoreContext Reassign <unknown> baz$2 = <unknown> $15
[11] <unknown> $17 = LoadLocal <unknown> foo$11
[12] <unknown> $18 = Call <unknown> $17()
[13] Return <unknown> $18冒頭のDeclareContext HoistedConstによってbar、bazがホイスティングされたことが分かる。
うーん、ここまで見ても特にピンとくるものがない。
それでは、ホイスティングをすべてオフにして生成してみよう。全部コメントアウトしてコンパイラを再実行した。
// 😴
case "BlockStatement": {
const stmt = stmtPath as NodePath<t.BlockStatement>;
const statements = stmt.get("body");
// const hoistableIdentifiers: Set<t.Identifier> = new Set();
// for (const [, binding] of Object.entries(stmt.scope.bindings)) {
// // refs to params are always valid / never need to be hoisted
// if (binding.kind !== "param") {
// hoistableIdentifiers.add(binding.identifier);
// }
// }
for (const s of statements) {
// const willHoist = new Set<NodePath<t.Identifier>>();
// /*
// * If we see a hoistable identifier before its declaration, it should be hoisted just
// * before the statement that references it.
// */
// let fnDepth = s.isFunctionDeclaration() ? 1 : 0;
// const withFunctionContext = {
// enter: (): void => {
// fnDepth++;
// },
// exit: (): void => {
// fnDepth--;
// },
// ...
lowerStatement(builder, s);
}まず、このようなエラーが発生した。
Todo: [hoisting] EnterSSA: Expected identifier to be defined before being used. \
Identifier bar$0 is undefined (5:5)何かが変わった。bar$0が定義される前に使用されたというエラーが発生した。
HIRコードも見てみよう。どんな違いが生じたのだろうか?
function hoisting
bb0 (block):
[1] <unknown> $1 = LoadLocal <unknown> bar$0
[2] <unknown> $3 = LoadLocal <unknown> baz$2
[3] <unknown> $8 = Function @deps[<unknown> $1,<unknown> $3] @context[<unknown> bar$0,<unknown> baz$2] @effects[]:
bb1 (block):
[1] <unknown> $4 = LoadLocal <unknown> bar$0
[2] <unknown> $5 = LoadLocal <unknown> baz$2
[3] <unknown> $6 = Binary <unknown> $4 + <unknown> $5
[4] Return <unknown> $6
[4] <unknown> $10 = StoreLocal Const <unknown> foo$9 = <unknown> $8
[5] <unknown> $11 = 3
[6] <unknown> $12 = StoreLocal Const <unknown> bar$0 = <unknown> $11
[7] <unknown> $13 = 2
[8] <unknown> $14 = StoreLocal Const <unknown> baz$2 = <unknown> $13
[9] <unknown> $15 = LoadLocal <unknown> foo$9
[10] <unknown> $16 = Call <unknown> $15()
[11] Return <unknown> $16おお… DeclareContext HoistedConstが消えた。これは当然のことだ。ホイスティングをしなかったのだから。
そのため**[1]で定義される前にLoadLocalが発生してエラーになったのだ。遅れて[6]、[8]**でStoreLocal Constとして定義されたが、すでに使用された後なのでエラーが発生した。
JavaScriptが実行される環境ではエンジンがホイスティングを行うが、HIRに変換された後は別の言語に変換されたのと変わらない。 そのため、できる限りJavaScriptをモデリングする必要があったのではないかと思う。 それ以外にも、これによってDCEやConst Propagationなど他の最適化過程でも後に活用できるのではないかという考えを残しておく。
そこで気になってCompilerの開発者であるlaurenに聞いてみた。質問を投げかけた後になって気まずくなりながらサンプルコードを探してみることになり、実装が必然的だったことを知った。
(質問の前半が少し切れているが)
it’s more because it’s a todo 🤣 const hoisting was the most straightforward to support, and at the moment it’s not used in any other passes
— lauren 나은 (@potetotes) June 9, 2024
このような親切な回答をいただいた。気になったときにすぐ質問できる勇気が(?)少しついた気がする。
constのホイスティングが最もシンプルにサポートできる形だったため先に実装され、まだ他の最適化過程では使用されていないとのことだった。
それでは、再びlowerStatement関数に戻って、他の部分を見ていこう。
再帰的に回りながら各ケースに応じたLoweringを実行していくことになる。これをすべて書き連ねていると、読む人も退屈だろうから、次回に手短にいくつかだけ見るか、この記事に後で追記しておくことにする。
とにかく、再帰的にbody部分をLoweringし終えると、以下の部分に抜けてくることになる。
builder.terminate(
{
kind: "return",
loc: GeneratedSource,
value: lowerValueToTemporary(builder, {
kind: "Primitive",
value: undefined,
loc: GeneratedSource,
}),
id: makeInstructionId(0),
},
null
);
return Ok({
id,
params,
fnType: parent == null ? env.fnType : "Other",
returnType: null, // TODO: extract the actual return type node if present
body: builder.build(),
context,
generator: func.node.generator === true,
async: func.node.async === true,
loc: func.node.loc ?? GeneratedSource,
env,
effects: null,
directives,
});builder.terminateを通じてreturnを生成し、builder.build()で生成して返す。
こうしてHIRFunctionが返される。
const hir = lower(func, env).unwrap();HIRに変換する過程でbuilderが多くの役割を担っているが、これについては深く見ることができなかった。次回さらに具体的に見ていくことにしよう。
まとめ
今回の記事ではlower関数を見てきた。
lower関数はBabel ASTからHIRFunctionを返す関数である。- 関数の引数、識別子、本体を抽出し、
HIRBuilderを通じてInstructionオブジェクトを生成する。 const変数宣言のホイスティングを処理する。lowerStatement関数を通じて各種文を処理する。lower関数は再帰的に呼び出され、関数の本体を処理してHIRFunctionを返す。
それでは、さようなら!
使用したツール
参考資料