Previously
In the last two parts, we looked at the compiler’s entry point and useMemoCache, which is a caching method.
From now on, let’s look at how the compiler parses and compiles through various processes.
Let’s revisit the compileFn function that actually performs the compilation, which we looked at in Part 1.
export function compileFn(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
config: EnvironmentConfig,
fnType: ReactFunctionType,
useMemoCacheIdentifier: string,
logger: Logger | null,
filename: string | null,
code: string | null
): CodegenFunction {
let generator = run(
func,
config,
fnType,
useMemoCacheIdentifier,
logger,
filename,
code
);
while (true) {
const next = generator.next();
if (next.done) {
return next.value;
}
}
}The compileFn function generates code through the run function and repeats the code generation process through generator.next().
// packages/babel-plugin-react-compiler/src/Entrypoint/Pipline.ts
export type CompilerPipelineValue =
| { kind: "ast"; name: string; value: CodegenFunction }
| { kind: "hir"; name: string; value: HIRFunction }
| { kind: "reactive"; name: string; value: ReactiveFunction }
| { kind: "debug"; name: string; value: string };
export function* run(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
config: EnvironmentConfig,
fnType: ReactFunctionType,
useMemoCacheIdentifier: string,
logger: Logger | null,
filename: string | null,
code: string | null
): Generator<CompilerPipelineValue, CodegenFunction> {
const contextIdentifiers = findContextIdentifiers(func);
const env = new Environment(
fnType,
config,
contextIdentifiers,
logger,
filename,
code,
useMemoCacheIdentifier
);
yield {
kind: "debug",
name: "EnvironmentConfig",
value: prettyFormat(env.config),
};
const ast = yield* runWithEnvironment(func, env);
return ast;
}
The run function creates an Environment and generates code through the runWithEnvironment function.
Environment is an object that manages global state and settings during the compilation process.
Let’s skip the details for now and move on.
Now let’s look at the runWithEnvironment function.
This is the function that actually generates the code.
runWithEnvironment
// packages/babel-plugin-react-compiler/src/Entrypoint/Pipline.ts
function* runWithEnvironment(
func: NodePath<
t.FunctionDeclaration | t.ArrowFunctionExpression | t.FunctionExpression
>,
env: Environment
): Generator<CompilerPipelineValue, CodegenFunction> {
const hir = lower(func, env).unwrap();
yield log({ kind: "hir", name: "HIR", value: hir });
pruneMaybeThrows(hir);
yield log({ kind: "hir", name: "PruneMaybeThrows", value: hir });
validateContextVariableLValues(hir);
validateUseMemo(hir);
dropManualMemoization(hir);
yield log({ kind: "hir", name: "DropManualMemoization", value: hir });
// ~~~~~~~~~~~~~~~~~~~~~
// --- 중간 여러 과정들 ---
// ~~~~~~~~~~~~~~~~~~~~~
const ast = codegenFunction(reactiveFunction, uniqueIdentifiers).unwrap();
yield log({ kind: "ast", name: "Codegen", value: ast });
/**
* This flag should be only set for unit / fixture tests to check
* that Forget correctly handles unexpected errors (e.g. exceptions
* thrown by babel functions or other unexpected exceptions).
*/
if (env.config.throwUnknownException__testonly) {
throw new Error("unexpected error");
}
// return the finally generated code
return ast;
}The entire process goes through about 40 steps to generate code.
Let’s first broadly categorize these steps as follows:
- ‘Lowering’: Convert AST to HIR (High-level Intermediate Representation)
- ‘Normalization, Optimization’: Process of normalizing and optimizing HIR
- ‘Static Analysis, Type Inference’: Convert to SSA form and infer types
- ‘Reactive Optimization’: Reactive optimization
- ‘Code Generation’: Code generation
Let’s break it down more specifically.
Don’t look too deeply into it yet, just skim through what processes there are.
- ‘Lowering’
lower: Convert AST to HIR
- ‘Optimization and Normalization’
pruneMaybeThrows: RemoveMaybeThrowsfrom HIRvalidateContextVariableLValues: Validate LValues of Context variables in HIRvalidateUseMemo: ValidateuseMemoin HIRdropManualMemoization: Remove manual memoizationinlineImmediatelyInvokedFunctionExpressions: Inline immediately invoked function expressions (IIFE)mergeConsecutiveBlocks: Merge consecutive blocks
- ‘Static Analysis and Type Inference’
enterSSA: Convert to SSA (Static Single Assignment) formeliminateRedundantPhi: Remove redundant Phi nodesconstantPropagation: Constant propagationinferTypes: Type inferencevalidateHooksUsage: Validate hooks usagevalidateNoCapitalizedCalls: Check for function calls starting with capital lettersanalyseFunctions: Analyze functionsinferReferenceEffects: Infer reference effectsdeadCodeElimination: Remove dead codeinferMutableRanges: Infer mutable rangesinferReactivePlaces: Infer reactive placesleaveSSA: Return from SSA form to normal form
- ‘Reactive Optimization (HIR)’
inferReactiveScopeVariables: Infer reactive scope variablesalignMethodCallScopes: Align method call scopesalignObjectMethodScopes: Align object method scopesmemoizeFbtOperandsInSameScope: Memoize Fbt operands in the same scopepruneUnusedLabelsHIR: Remove unused labelsalignReactiveScopesToBlockScopesHIR: Align reactive scopes to block scopesmergeOverlappingReactiveScopesHIR: Merge overlapping reactive scopesbuildReactiveScopeTerminalsHIR: Build reactive scope terminalsbuildReactiveFunction: Build reactive function
- ‘Reactive Optimization (Reactive function)’
pruneUnusedLabels: Remove unused labelsflattenReactiveLoops: Flatten reactive loopspropagateScopeDependencies: Propagate scope dependenciespruneNonReactiveDependencies: Remove non-reactive dependenciespruneUnusedScopes: Remove unused scopesmergeReactiveScopesThatInvalidateTogether: Merge reactive scopes that invalidate togetherpruneAlwaysInvalidatingScopes: Remove always invalidating scopespropagateEarlyReturns: Propagate early returnspromoteUsedTemporaries: Promote used temporariespruneUnusedLValues: Remove unused LValuesextractScopeDeclarationsFromDestructuring: Extract scope declarations from destructuringstabilizeBlockIds: Stabilize block IDsrenameVariables: Rename variablespruneHoistedContexts: Remove hoisted contexts
- ‘Code Generation’
codegenFunction: Generate final code
We may not look at all the processes, but let’s start for now.
Lowering
const hir = lower(func, env).unwrap();The first step of the React compiler, Lowering, is the process of converting AST (Abstract Syntax Tree) to HIR (High-level Intermediate Representation).
Let’s first revisit the concept of compilation.
to collect information from different places and arrange it in a book, report, or list
[Cambridge Dictionary]
The dictionary meaning is to collect various information and organize it into a book, report, or list.
In computer science, compilation refers to the process of converting source code to machine code.
Changing to machine code. In simple terms, it means changing to a language that computers can understand.
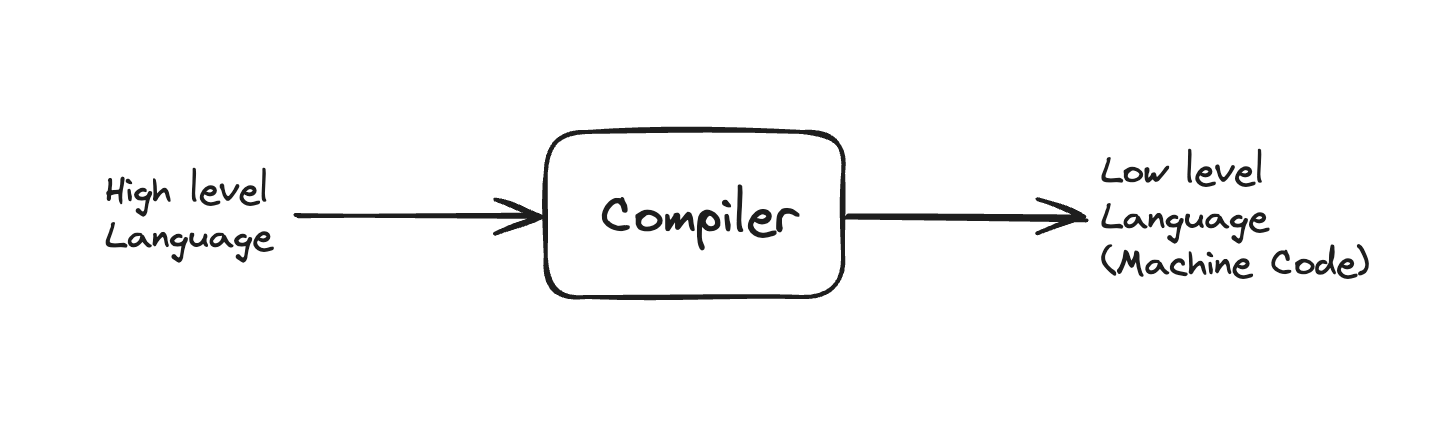
The source code was converted to AST by Babel, and this AST is further lowered to an intermediate representation (IR), hence it’s called Lowering.
Now let’s look at the lower function that converts to HIR.
// packages/babel-plugin-react-compiler/src/HIR/BuildHIR.ts
/*
* Converts a function into a high-level intermediate form (HIR) which represents
* the code as a control-flow graph. All normal control-flow is modeled as accurately
* as possible to allow precise, expression-level memoization. The main exceptions are
* try/catch statements and exceptions: we currently bail out (skip compilation) for
* try/catch and do not attempt to model control flow of exceptions, which can occur
* ~anywhere in JavaScript. The compiler assumes that exceptions will be handled by
* the runtime, ie by invalidating memoization.
*/
export function lower(
func: NodePath<t.Function>,
env: Environment,
bindings: Bindings | null = null,
capturedRefs: Array<t.Identifier> = [],
// the outermost function being compiled, in case lower() is called recursively (for lambdas)
parent: NodePath<t.Function> | null = null
): Result<HIRFunction, CompilerError> {
// ...
}Referring to the comment above the function, it says that it converts AST (Abstract Syntax Tree) to a high-level intermediate representation (HIR) that represents it as a CFG (Control-Flow Graph, hereafter CFG).
AST (Abstract Syntax Tree) is a tree-like data structure representing the syntax of a program, while CFG (Control Flow Graph) is a graph-like data structure representing the control flow of a program.
Each node in the graph represents a continuous part of the code called a basic block, and the edges represent the control flow from one basic block to another.
Control flow structures refer to branches and loops such as if/else, switch, and loop.
CFG captures all possible execution paths of a program and is used for code optimization and analysis.
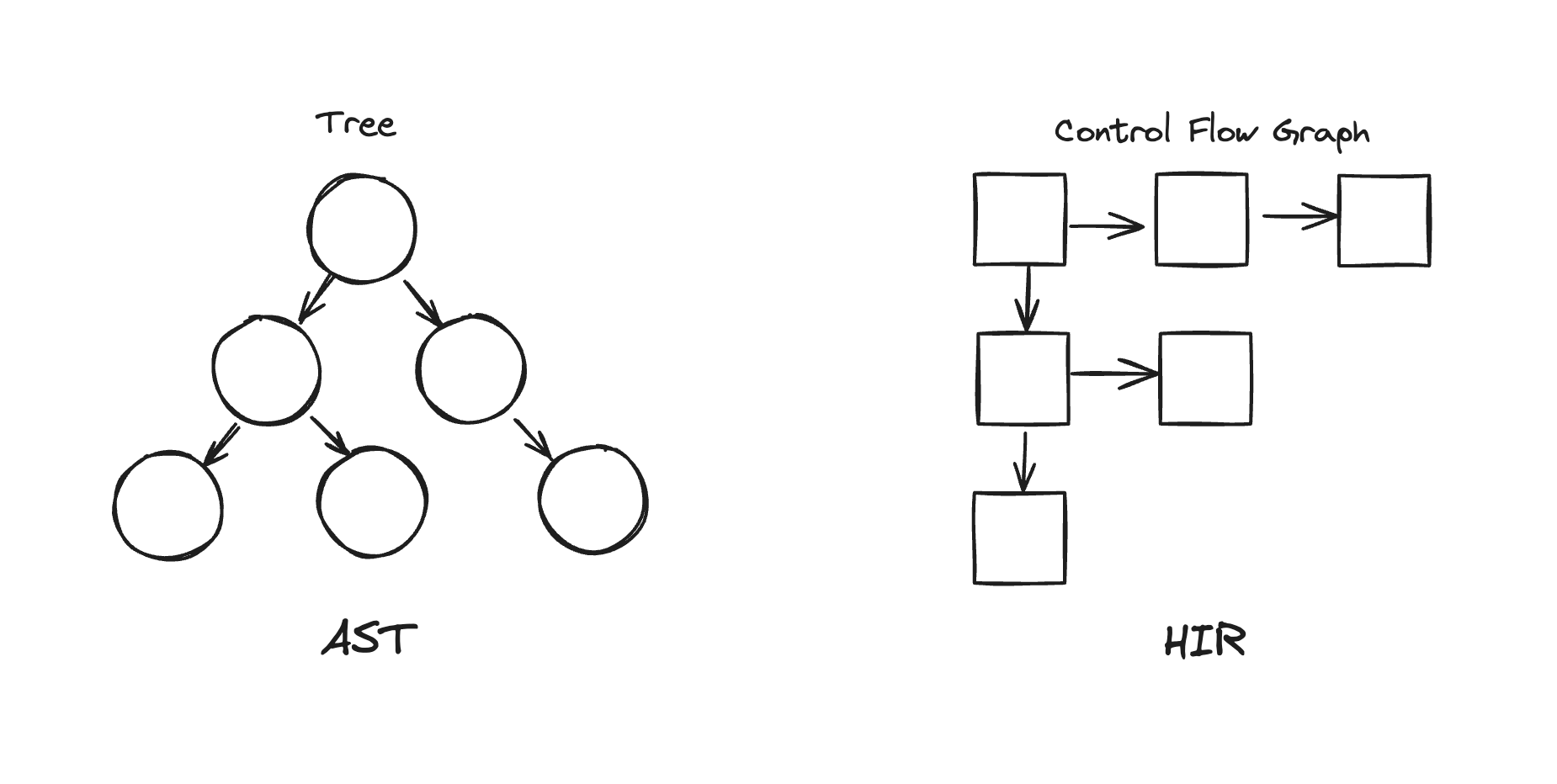
The diagram is drawn like this, but each node doesn’t match each other.
To help understanding, let’s first look at the result.
The following is the result of converting simple code to AST and HIR.
function Component({ color }: { color: string }) {
if (color === "red") {
return (<div styles={{ color }}>hello red</div>)
} else {
return (<div styles={{ color }}>hello etc</div>)
}
}This is an example code to help understanding. The Component function returns different JSX depending on whether color is red or not.
When this code is represented as AST, it will be expressed as a tree for the following syntax.
// Component Function
FunctionDeclaration
Identifier
Parameter
ObjectBindingPattern
BindingElement
Identifier
TypeLiteral
Block
IfStatement
BinaryExpression
Identifier
EqualsEqualsEqualsToken
StringLiteral
Block
ReturnStatement
ParenthesizedExpression
JsxElement
JsxOpeningElement
Identifier
//...
//...The graph representation would look like this:
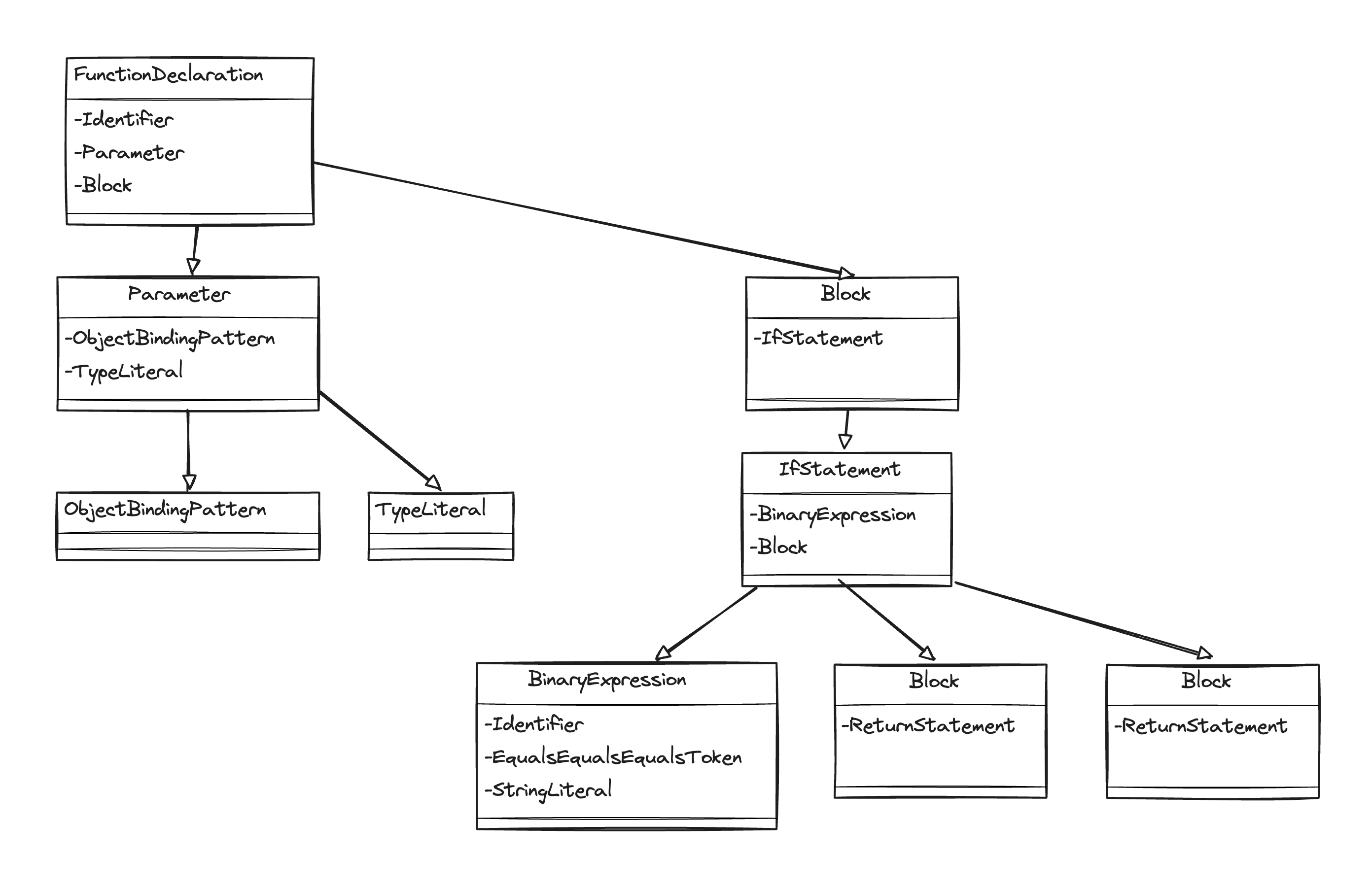
Now when this AST is converted to HIR, it looks like this:
function Component
bb0 (block):
[1] <unknown> $2 = Destructure Let { color: <unknown> color$1 } = <unknown> $0
[2] <unknown> $11 = LoadLocal <unknown> color$1
[3] <unknown> $12 = "red"
[4] <unknown> $13 = Binary <unknown> $11 === <unknown> $12
[5] If (<unknown> $13) then:bb2 else:bb4 fallthrough=bb1
bb2 (block):
predecessor blocks: bb0
[6] <unknown> $3 = LoadLocal <unknown> color$1
[7] <unknown> $4 = Object { color: <unknown> $3 }
[8] <unknown> $5 = JSXText "hello red"
[9] <unknown> $6 = JSX <div styles={<unknown> $4} >{<unknown> $5}</div>
[10] Return <unknown> $6
bb4 (block):
predecessor blocks: bb0
[11] <unknown> $7 = LoadLocal <unknown> color$1
[12] <unknown> $8 = Object { color: <unknown> $7 }
[13] <unknown> $9 = JSXText "hello etc"
[14] <unknown> $10 = JSX <div styles={<unknown> $8} >{<unknown> $9}</div>
[15] Return <unknown> $10
bb1 (block):
[16] UnreachableYou don’t need to understand the code here. Just skim through it.
In this example code, the control flow is the if statement within the Component function. Accordingly, the Component function is divided into four basic blocks: bb0, bb2, bb4, and bb1.
[5] If (<unknown> $13) then:bb2 else:bb4 fallthrough=bb1This part shows the flow going to bb2 through the If statement, the case going to bb4, and the flow going to bb1 through fallthrough.
fallthrough represents the flow after passing through the if statement. In this case, it’s marked as unreachable code.
To help understanding, if we draw it as a picture, it looks like this:
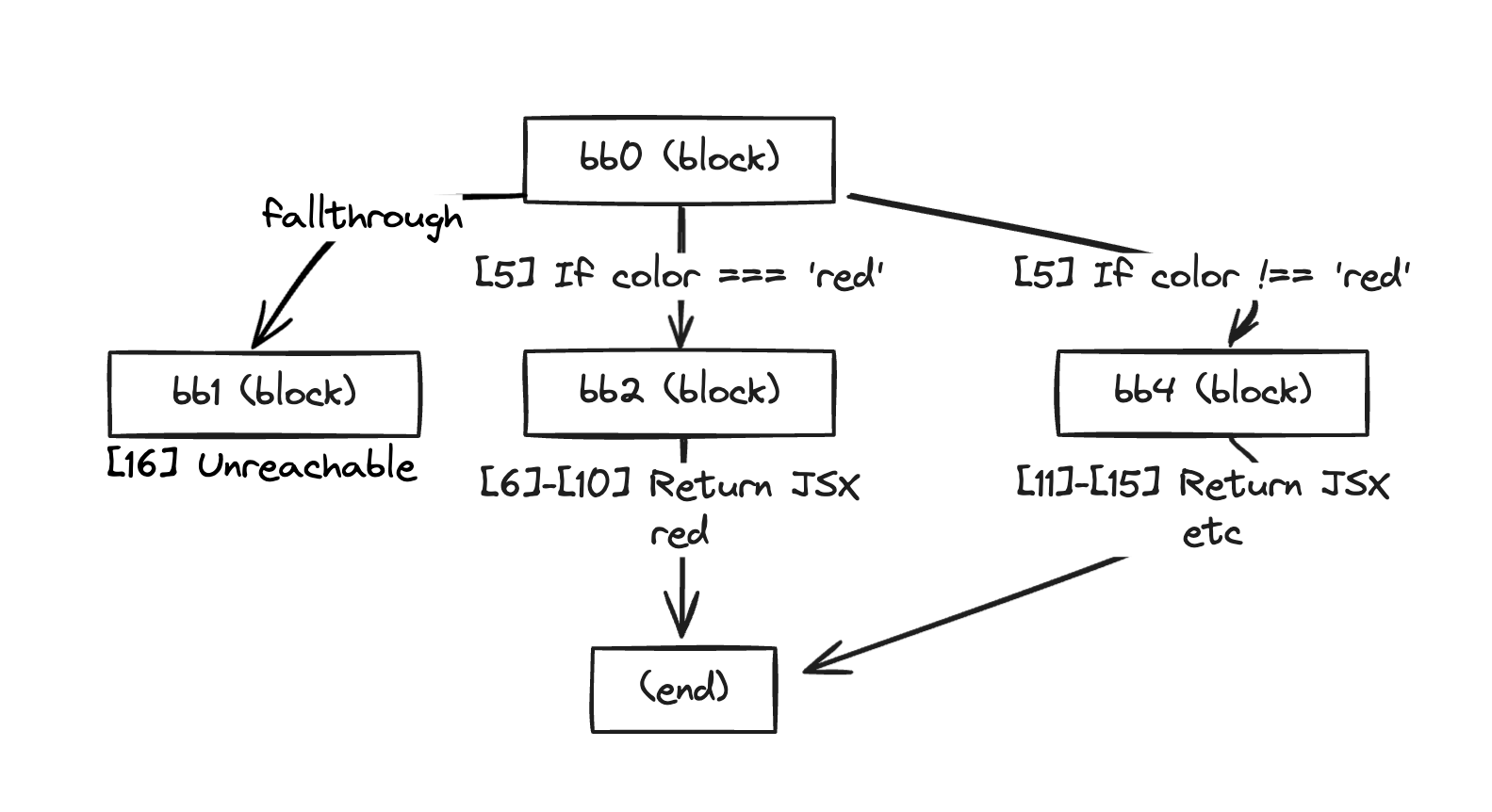
Ah~ Now we’re starting to get a sense of what the transformation looks like.
This transformation process of expressing a syntax tree in this form of a graph according to control flow is called Lowering.
And the representation form after transformation is called HIR. (In React Compiler)
Exit Point
Even if we only look this far, we can roughly understand what kind of data structure HIR represents, which should be sufficient for understanding the compilation process.
Therefore, you can move on to the next part right away.
Detach!
Back to the lower function
From here on, we’ll look at the lowering process out of simple intellectual curiosity. It includes the lowering process for all statements. The code itself is about 4,000 lines long.
So let’s take a look step by step.
Let’s go back to the beginning and look at the lower function again.
export function lower(
func: NodePath<t.Function>,
env: Environment,
bindings: Bindings | null = null,
capturedRefs: Array<t.Identifier> = [],
// the outermost function being compiled, in case lower() is called recursively (for lambdas)
parent: NodePath<t.Function> | null = null
): Result<HIRFunction, CompilerError> {}The lower function takes a NodePath<t.Function> derived from Babel as input and returns an HIRFunction. (It returns a CompilerError if an error occurs.)
Other arguments include the Environment object, Bindings, capturedRefs, and parent.
What is the unit of the func that comes in as input?
Let’s recall what we looked at in Part 1.
We traversed through the program node’s traverse method, found nodes for functions, and passed those nodes to the compileFn function.
Therefore, func will be a node for a function coming from the Babel AST.
It will be either FunctionDeclaration, FunctionExpression, or ArrowFunctionExpression.
Continuing on…
const builder = new HIRBuilder(env, parent ?? func, bindings, capturedRefs);
const context: Array<Place> = [];An instance of HIRBuilder is created and assigned, and the context array is initialized. This is an array that holds function context information.
for (const ref of capturedRefs ?? []) {
context.push({
kind: "Identifier",
identifier: builder.resolveBinding(ref),
effect: Effect.Unknown,
reactive: false,
loc: ref.loc ?? GeneratedSource,
});
}It iterates through the capturedRefs array and adds a Place object to the context array.
This part is for recursive calls, so let’s skip it for now and come back to it later.
함수 이름 추출(식별자, Identifier)
If the function is a FunctionDeclaration or FunctionExpression, it gets the function’s id (Identifier) and assigns it to the id variable.
let id: string | null = null;
if (func.isFunctionDeclaration() || func.isFunctionExpression()) {
const idNode = (
func as NodePath<t.FunctionDeclaration | t.FunctionExpression>
).get("id");
if (hasNode(idNode)) {
id = idNode.node.name;
}
}FunctionDeclaration nodes and FunctionExpression nodes can have identifiers, but ArrowFunctionExpression nodes cannot have identifiers.
// FunctionDeclaration
function foo() {}
// FunctionExpression
const foo = function bar() {}
// ArrowFunctionExpression
const foo = () => {}Extracting Arguments (Parameters)
It extracts the function’s arguments and adds Place objects to the params array.
params: Array<Identifier | Pattern | RestElement> (required)params can contain Identifier, Pattern, RestElement.
Identifier is an identifier, Pattern is an object or array pattern, and RestElement represents the rest element.
const params: Array<Place | SpreadPattern> = [];
func.get("params").forEach((param) => {
if (param.isIdentifier()) {}
else if (param.isObjectPattern() || param.isArrayPattern() || param.isAssignmentPattern()) {}
else if (param.isRestElement()) {}
else {}
// ...
});Identifier (single variable name)
// example
const greet = function(name) { // name is Identifier
console.log(`Hello, ${name}!`);
};If the argument is an Identifier, it creates a Place object and adds it to the params array.
if (param.isIdentifier()) {
const binding = builder.resolveIdentifier(param);
const place: Place = {
kind: "Identifier",
identifier: binding.identifier,
effect: Effect.Unknown,
reactive: false,
loc: param.node.loc ?? GeneratedSource,
};
params.push(place);
}The Place object that will appear frequently from now on is defined as follows:
export type Place = {
kind: "Identifier";
identifier: Identifier;
effect: Effect; // The effect with which a value is modified.
reactive: boolean;
loc: SourceLocation;
};ObjectPattern (object pattern), ArrayPattern (array pattern), AssignmentPattern (assignment pattern)
// example
// ObjectPattern
const greet = function({ name }) {
console.log(`Hello, ${name}!`);
};
// ArrayPattern
const greet = function([name]) {
console.log(`Hello, ${name}!`);
};
// AssignmentPattern
const greet = function(name = 'world') {
console.log(`Hello, ${name}!`);
};
If the argument is ObjectPattern, ArrayPattern, or AssignmentPattern, it creates a temporary variable, creates a Place object, and adds it to the params array.
It handles the assignment through the lowerAssignment function.
else if (
param.isObjectPattern() ||
param.isArrayPattern() ||
param.isAssignmentPattern()
) {
const place: Place = {
kind: "Identifier",
identifier: builder.makeTemporary(),
effect: Effect.Unknown,
reactive: false,
loc: param.node.loc ?? GeneratedSource,
};
params.push(place);
lowerAssignment(
builder,
param.node.loc ?? GeneratedSource,
InstructionKind.Let,
param,
place,
"Assignment"
);
}RestElement (rest element)
// example
const greet = function(...names) {
console.log(`Hello, ${names.join(', ')}!`);
};If the argument is RestElement, it creates a temporary variable, creates a Spread object, and adds it to the params array.
else if (param.isRestElement()) {
const place: Place = {
kind: "Identifier",
identifier: builder.makeTemporary(),
effect: Effect.Unknown,
reactive: false,
loc: param.node.loc ?? GeneratedSource,
};
params.push({
kind: "Spread",
place,
});
lowerAssignment(
builder,
param.node.loc ?? GeneratedSource,
InstructionKind.Let,
param.get("argument"),
place,
"Assignment"
);
}This is the process of extracting the function’s arguments and adding Place objects to the params array.
Now let’s look at the process of extracting the function’s body and adding Instruction objects to the body array.
Extracting Function Body (Body)
let directives: Array<string> = [];
const body = func.get("body");It extracts the function’s body and initializes the directives array.
Expression
if (body.isExpression()) {
const fallthrough = builder.reserve("block");
const terminal: ReturnTerminal = {
kind: "return",
loc: GeneratedSource,
value: lowerExpressionToTemporary(builder, body),
id: makeInstructionId(0),
};
builder.terminateWithContinuation(terminal, fallthrough);
}BlockStatement
In the case of a block statement, it processes the body through the lowerStatement function.
else if (body.isBlockStatement()) {
lowerStatement(builder, body);
directives = body.get("directives").map((d) => d.node.value.value);
}This part can actually be considered the core part.
Let’s look at the lowerStatement function.
function lowerStatement(
builder: HIRBuilder,
stmtPath: NodePath<t.Statement>,
label: string | null = null
): void {
const stmtNode = stmtPath.node;
switch (stmtNode.type) {
case "ThrowStatement":
case "ReturnStatement":
case "IfStatement":
case "BlockStatement":
case "BreakStatement":
case "ContinueStatement":
case "ForStatement":
case "WhileStatement":
case "LabeledStatement":
case "SwitchStatement":
case "VariableDeclaration":
case "ExpressionStatement":
case "DoWhileStatement":
case "FunctionDeclaration":
case "ForOfStatement":
case "ForInStatement":
case "DebuggerStatement":
case "EmptyStatement":
case "TryStatement":
// ------- skip -------
case "TypeAlias":
case "TSTypeAliasDeclaration":
// --- unsupported ---
case "ClassDeclaration":
// ~
case "WithStatement":
default:The lowerStatement function performs various processes depending on the node type of stmtPath (Statement Path).
When called by the lower function, stmtPath will be a BlockStatement. So let’s look at an example.
// example
function complexExample(x) {
let result = 0;
if (x > 0) {
result = x * 2;
} else {
result = x * 3;
}
return result;
}function complexExample has a BlockStatement as its body. Let’s pass this BlockStatement to the lowerStatement function.
case "BlockStatement": {
const stmt = stmtPath as NodePath<t.BlockStatement>;
const statements = stmt.get("body");It type casts stmtPath to BlockStatement and extracts the body.
body is of type NodePath<t.Statement>[], representing each statement in the block statement.
for (const s of statements) {
lowerStatement(builder, s);
}It iterates through the statements, calling the lowerStatement function recursively.
Besides the process of recursively processing during blockStatement handling, there’s one more process.
Handling ‘const’ Variable Declaration Hoisting
First, it checks if a binding can be hoisted before it’s declared,
then hoists the declaration as a context variable to the earliest point where it’s referenced (i.e., right before the topmost statement).
const hoistableIdentifiers: Set<t.Identifier> = new Set();
for (const [, binding] of Object.entries(stmt.scope.bindings)) {
// refs to params are always valid / never need to be hoisted
if (binding.kind !== "param") {
hoistableIdentifiers.add(binding.identifier);
}
}It creates a Set called hoistableIdentifiers and iterates through stmt.scope.bindings,
adding identifiers to hoistableIdentifiers.
stmt.scope.bindings contains binding information for the current block.
It doesn’t include binding information for parent or child blocks.
At this time, const, let, var are added to hoistableIdentifiers.
When iterating through each statement, it creates a Set called willHoist to contain elements that need to be hoisted.
for (const s of statements) {
const willHoist = new Set<NodePath<t.Identifier>>();
// ...
}It tracks the depth of the function context. This is to track whether identifier references occur in inner functions.
While traversing through traverse, when it encounters FunctionExpression, FunctionDeclaration, ArrowFunctionExpression, ObjectMethod nodes, it increases the function depth, and when it exits the node, it decreases the function depth.
let fnDepth = s.isFunctionDeclaration() ? 1 : 0;
const withFunctionContext = {
enter: (): void => {
fnDepth++; // function depth increase
},
exit: (): void => {
fnDepth--; // function depth decrease
},
};
s.traverse({
FunctionExpression: withFunctionContext, // function expression
FunctionDeclaration: withFunctionContext, // function declaration
ArrowFunctionExpression: withFunctionContext, // arrow function expression
ObjectMethod: withFunctionContext, // object method
// ...
});While iterating through the statements, it looks for identifiers.
If the identifier is not referenced or its parent is not an assignment expression, it skips.
If the identifier is referenced and is in hoistableIdentifiers, and the function depth is greater than 0 or the binding is hoisted, it’s added to willHoist.
s.traverse({
// ...
Identifier(id: NodePath<t.Identifier>) {
const id2 = id;
if (
!id2.isReferencedIdentifier() &&
// isReferencedIdentifier is broken and returns false for reassignments
id.parent.type !== "AssignmentExpression"
) {
return;
}
const binding = id.scope.getBinding(id.node.name);
/*
* The cases where an identifier declaration can be hoisted are as follows:
* 1. When the reference occurs within an inner function
* or
* 2. When the declaration itself is hoistable
*/
if (
binding != null &&
hoistableIdentifiers.has(binding.identifier) &&
(fnDepth > 0 || binding.kind === "hoisted")
) {
willHoist.add(id);
}
},
});Then it iterates through the node again, removing identifiers that are in hoistableIdentifiers.
s.traverse({
Identifier(path: NodePath<t.Identifier>) {
if (hoistableIdentifiers.has(path.node)) {
hoistableIdentifiers.delete(path.node);
}
},
});It iterates through willHost, converts the identifier to a unique identifier through resolveIdentifier,
creates DeclareContext in a temporary variable through the lowerValueToTemporary function and pushes it to the builder.
Then it adds to the global environment’s #contextIdentifiers, #hoistedIdentifiers.
// Hoist declarations that need it to the earliest point where they are needed
for (const id of willHoist) {
const binding = stmt.scope.getBinding(id.node.name);
if (builder.environment.isHoistedIdentifier(binding.identifier)) {
// Already hoisted
continue;
}
const identifier = builder.resolveIdentifier(id);
const place: Place = {
effect: Effect.Unknown,
identifier: identifier.identifier,
kind: "Identifier",
reactive: false,
loc: id.node.loc ?? GeneratedSource,
};
lowerValueToTemporary(builder, {
kind: "DeclareContext",
lvalue: {
kind: InstructionKind.HoistedConst,
place,
},
loc: id.node.loc ?? GeneratedSource,
});
builder.environment.addHoistedIdentifier(binding.identifier);Later, before code generation, it removes DeclareContext and retransforms the associated StoreContext to restore the original source code.
Hoisting for other types of declarations is planned to be implemented in the future.
Why do we do hoisting?
However, what we’ve just looked at is hoisting done by the compiler.
Why do we do const hoisting? Let’s look at an example. We can get quality examples through test code. Let’s move to /src/__tests__/fixtures/compiler.
I picked one code that looks concise. Let’s open the “hoisting-simple-const-declaration.expected.md” file.
function hoisting() {
const foo = () => {
return bar + baz;
};
const bar = 3;
const baz = 2;
return foo(); // OK: called outside of TDZ for bar/baz
}This is a simple hoisting example. When this is converted to HIR, it changes like this:
function hoisting
bb0 (block):
[1] <unknown> $1 = DeclareContext HoistedConst <unknown> bar$0
[2] <unknown> $3 = DeclareContext HoistedConst <unknown> baz$2
[3] <unknown> $4 = LoadContext <unknown> bar$0
[4] <unknown> $5 = LoadContext <unknown> baz$2
[5] <unknown> $10 = Function @deps[<unknown> $4,<unknown> $5] @context[<unknown> bar$0,<unknown> baz$2] @effects[]:
bb1 (block):
[1] <unknown> $6 = LoadContext <unknown> bar$0
[2] <unknown> $7 = LoadContext <unknown> baz$2
[3] <unknown> $8 = Binary <unknown> $6 + <unknown> $7
[4] Return <unknown> $8
[6] <unknown> $12 = StoreLocal Const <unknown> foo$11 = <unknown> $10
[7] <unknown> $13 = 3
[8] <unknown> $14 = StoreContext Reassign <unknown> bar$0 = <unknown> $13
[9] <unknown> $15 = 2
[10] <unknown> $16 = StoreContext Reassign <unknown> baz$2 = <unknown> $15
[11] <unknown> $17 = LoadLocal <unknown> foo$11
[12] <unknown> $18 = Call <unknown> $17()
[13] Return <unknown> $18You can see that bar and baz have been hoisted through DeclareContext HoistedConst at the top.
Hmm, nothing particularly striking so far.
Then let’s try generating with all hoisting turned off. I commented out everything and ran the compiler again.
// 😴
case "BlockStatement": {
const stmt = stmtPath as NodePath<t.BlockStatement>;
const statements = stmt.get("body");
// const hoistableIdentifiers: Set<t.Identifier> = new Set();
// for (const [, binding] of Object.entries(stmt.scope.bindings)) {
// // refs to params are always valid / never need to be hoisted
// if (binding.kind !== "param") {
// hoistableIdentifiers.add(binding.identifier);
// }
// }
for (const s of statements) {
// const willHoist = new Set<NodePath<t.Identifier>>();
// /*
// * If we see a hoistable identifier before its declaration, it should be hoisted just
// * before the statement that references it.
// */
// let fnDepth = s.isFunctionDeclaration() ? 1 : 0;
// const withFunctionContext = {
// enter: (): void => {
// fnDepth++;
// },
// exit: (): void => {
// fnDepth--;
// },
// ...
lowerStatement(builder, s);
}First, this error occurred:
Todo: [hoisting] EnterSSA: Expected identifier to be defined before being used. \
Identifier bar$0 is undefined (5:5)Something has changed. An error occurred saying that bar$0 was used before it was defined.
Let’s also look at the HIR code. What difference has occurred?
function hoisting
bb0 (block):
[1] <unknown> $1 = LoadLocal <unknown> bar$0
[2] <unknown> $3 = LoadLocal <unknown> baz$2
[3] <unknown> $8 = Function @deps[<unknown> $1,<unknown> $3] @context[<unknown> bar$0,<unknown> baz$2] @effects[]:
bb1 (block):
[1] <unknown> $4 = LoadLocal <unknown> bar$0
[2] <unknown> $5 = LoadLocal <unknown> baz$2
[3] <unknown> $6 = Binary <unknown> $4 + <unknown> $5
[4] Return <unknown> $6
[4] <unknown> $10 = StoreLocal Const <unknown> foo$9 = <unknown> $8
[5] <unknown> $11 = 3
[6] <unknown> $12 = StoreLocal Const <unknown> bar$0 = <unknown> $11
[7] <unknown> $13 = 2
[8] <unknown> $14 = StoreLocal Const <unknown> baz$2 = <unknown> $13
[9] <unknown> $15 = LoadLocal <unknown> foo$9
[10] <unknown> $16 = Call <unknown> $15()
[11] Return <unknown> $16Oh… DeclareContext HoistedConst disappeared. This is natural, of course. We didn’t do hoisting.
As a result, LoadLocal occurred before definition in [1], causing an error. Although it was defined later with StoreLocal Const in [6] and [8], an error occurred because it had already been used.
In the environment where JavaScript is executed, the engine does the hoisting, but once it’s converted to HIR, it’s no different from being converted to another language. Therefore, I think they had to model JavaScript as much as possible. Besides, I think it could be used later in other optimization processes such as DCE or Const Propagation.
So out of curiosity, I asked the Compiler developer lauren. Only after asking the question did I embarrassingly find the example code and realized that the implementation was inevitable.
(The front part of the question got cut off)
it’s more because it’s a todo 🤣 const hoisting was the most straightforward to support, and at the moment it’s not used in any other passes
— lauren 나은 (@potetotes) June 9, 2024
I received such a kind answer. I think I’ve gained a little courage to ask questions right away when I’m curious.
She says that const hoisting was the simplest form to support, so it was implemented first, and it hasn’t been used in other optimization processes yet.
Then, let’s go back to the lowerStatement function and look at other parts.
Now it will perform lowering according to each case while recursively turning. If I were to write all of this, I think the reader would get bored too. So I’ll briefly look at a few in the next time or append it to this article later.
Anyway, after recursively lowering the body part, it will fall out below.
builder.terminate(
{
kind: "return",
loc: GeneratedSource,
value: lowerValueToTemporary(builder, {
kind: "Primitive",
value: undefined,
loc: GeneratedSource,
}),
id: makeInstructionId(0),
},
null
);
return Ok({
id,
params,
fnType: parent == null ? env.fnType : "Other",
returnType: null, // TODO: extract the actual return type node if present
body: builder.build(),
context,
generator: func.node.generator === true,
async: func.node.async === true,
loc: func.node.loc ?? GeneratedSource,
env,
effects: null,
directives,
});It generates a return through builder.terminate and returns by generating through builder.build().
That’s how it returns an HIRFunction.
const hir = lower(func, env).unwrap();The builder plays a big role in the process of converting to HIR, which we didn’t look at in depth. We’ll look at this more specifically next time.
Wrap-up
In this article, we looked at the lower function.
- The
lowerfunction is a function that returns anHIRFunctionfrom the Babel AST. - It extracts the function’s arguments, identifiers, and body and creates
Instructionobjects throughHIRBuilder. - It handles hoisting of
constvariable declarations. - It processes various statements through the
lowerStatementfunction. - The
lowerfunction is called recursively, processes the function’s body, and returns anHIRFunction.
Goodbye then!
Tools used
References